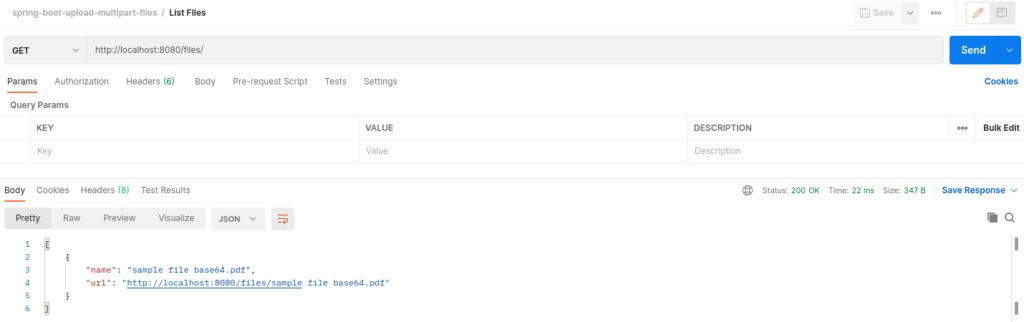
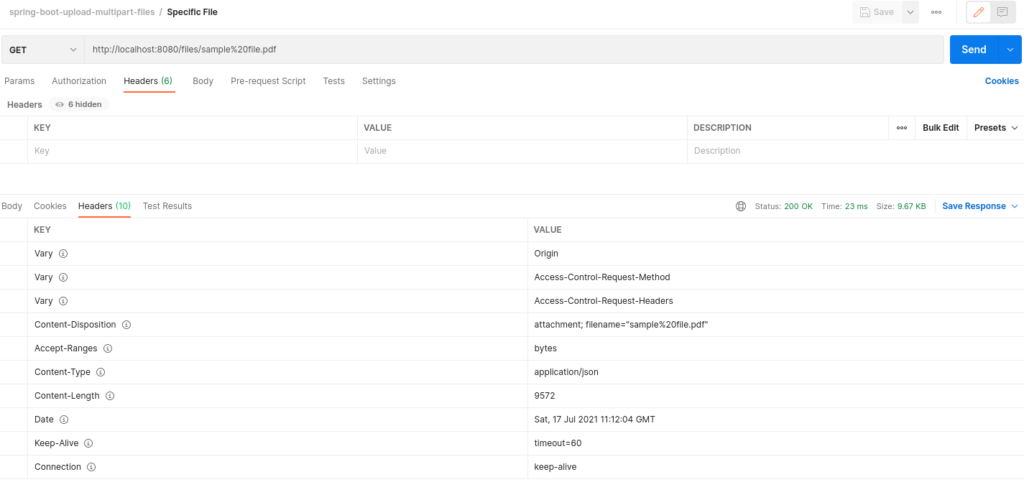
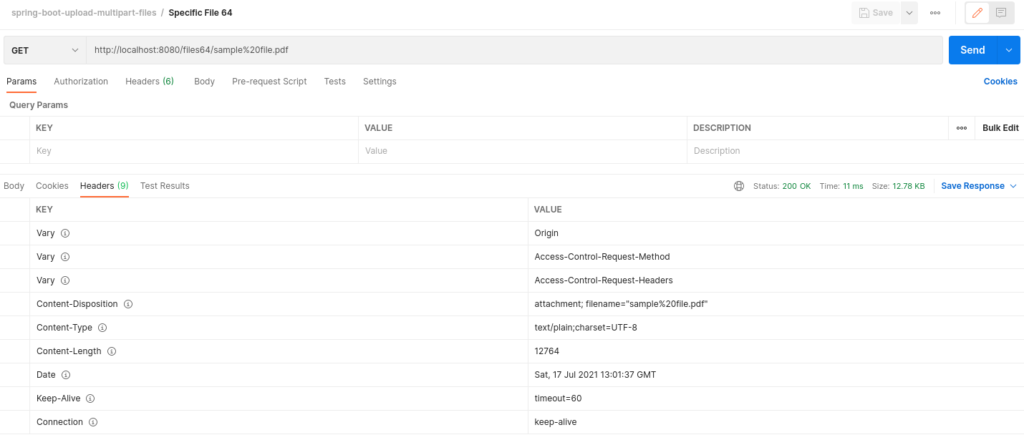
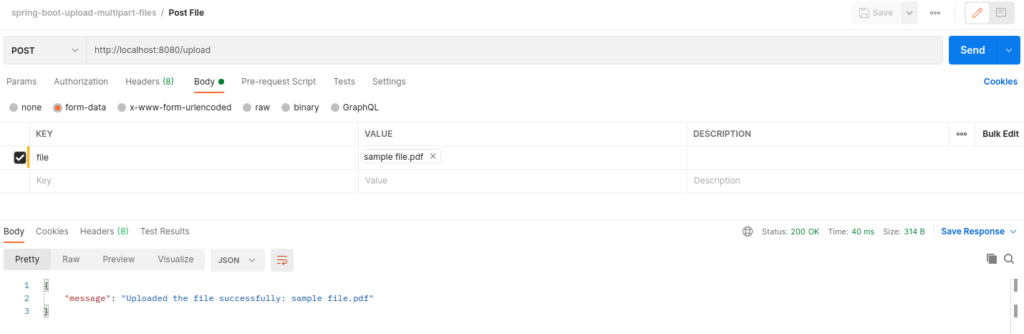
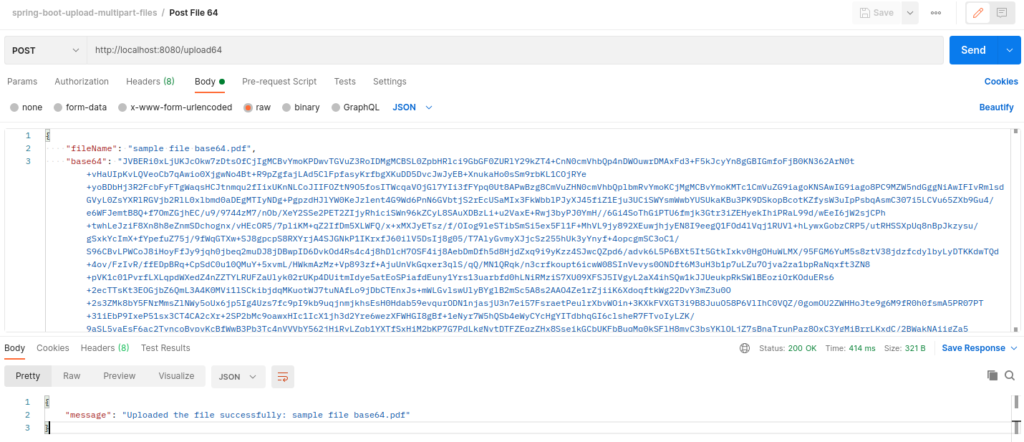
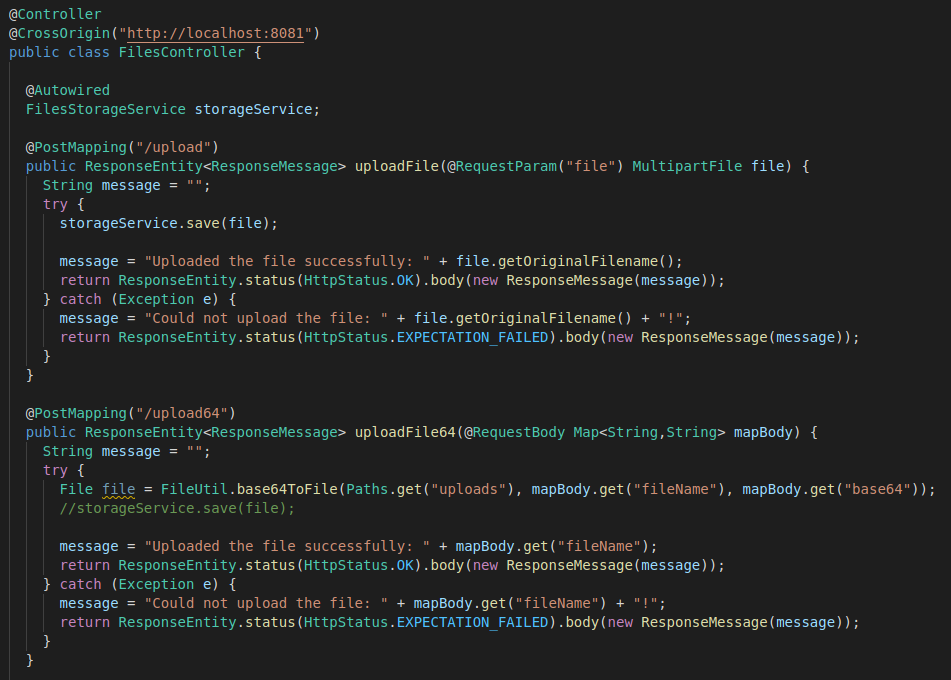
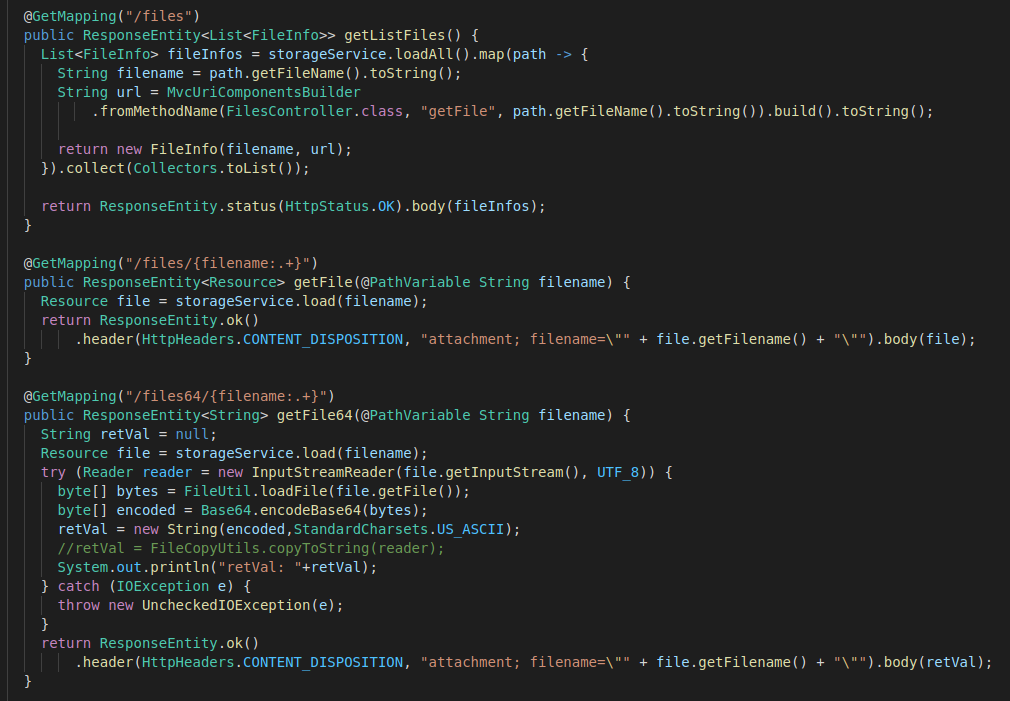
Este post, esclarece as diferenças de uma API que permite integrar arquivos, através de arquivo binário e base 64. Um ponto importante é que utilizando o formato Base 64, o payload aumenta 33% (em média), nas chamadas GET/POST.
GET – Specif File 64 (obtenção do arquivo em base64 – em torno de 33% maior que o binário) – Verifique o tamanho em Content-Length (12.764) – O arquivo binário tem 9.572 bytes.
Como o R é um projeto em constante atualização, a versão estável mais recente nem sempre está disponível nos repositórios do Ubuntu. Sendo assim, vamos começar adicionando o repositório externo mantido pelo CRAN.
Nota: o CRAN mantém os repositórios dentro de sua rede, mas nem todos os repositórios externos são confiáveis. Certifique-se de instalar apenas a partir de fontes confiáveis.
Ao executarmos o programa, vamos receber o seguinte resultado:
OutputExecuting: /tmp/apt-key-gpghome.cul0ddtmN1/gpg.1.sh --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9
gpg: key 51716619E084DAB9: public key "Michael Rutter <marutter@gmail.com>" imported
gpg: Total number processed: 1
gpg: imported: 1
Assim que tivermos a chave confiável, podemos adicionar o repositório.
Se você não estiver usando a versão 20.04, será possível encontrar o repositório relevante da lista Ubuntu do projeto R, nomeada para cada versão. O Ubuntu 20.04 é conhecido como Focal Fossa, e a versão mais recente do R é a 4.1.0. Por conta disso, este é o nome convencionado do repositório abaixo — focal-cran40.
Se a linha acima aparecer no resultado do comando update, adicionamos o repositório com sucesso. Podemos garantir que não instalaremos acidentalmente uma versão mais antiga.
Neste ponto, estamos prontos para instalar o R com o seguinte comando.
$ sudo apt install r-base
Copy
Se for solicitado a confirmar a instalação, pressione y para continuar.
No momento em que este tutorial está sendo escrito, a versão estável mais recente do R do CRAN é a 4.1.0, que é exibida quando você inicia o R.
Como estamos planejando instalar um pacote de exemplo para cada usuário no sistema, iniciaremos o R como root para que as bibliotecas estejam disponíveis para todos os usuários automaticamente. De forma alternativa, se você executar o comando R sem o sudo, uma biblioteca pessoal pode ser configurada para seu usuário.
$ sudo -i R
Copy
Output
R version 4.0.0 (2020-04-24) -- "Arbor Day"
Copyright (C) 2020 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
...
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>
Isso confirma que instalamos o R com sucesso e entramos em seu shell interativo.
Para verificar a versão instalada, digite o comando
Input and initial processing—Taking in speech or text and breaking it up into smaller pieces for processing. For speech, this step is called phonetic analysis, and consists of breaking down the speech into individual sounds, called phonemes. For text input, this can include optical character recognition (OCR) and tokenization. OCR is used to recognize the individual characters in text if it’s coming in as an image rather than as words made of characters. Tokenization refers to breaking down a continuous text into individual tokens, often words.
Morphological analysis—Breaking down complex words into their components to better understand their meaning. For example, you can break down “incomprehensible” into its component parts.
“in”—not
“comprehens”—to understand or comprehend
“ible”—indicates that this word is an adjective, describing whether something can be comprehended
Syntactic analysis—Trying to understand the structure of sentences by looking at how the words work together. This step is like diagramming a sentence, where you identify the role each word is playing in the sentence.
Semantic interpretation—Working out the meaning of a sentence by combining the meaning of individual words with their syntactic roles in the sentence.
Discourse processing—Understanding the context around a sentence to fully process what it means.
O Docker é um aplicativo que simplifica o processo de gerenciamento de processos de aplicação em containers. Os containers deixam você executar suas aplicações em processos isolados de recurso. Eles são semelhantes a máquinas virtuais, mas os containers são mais portáveis, mais fáceis de usar e mais dependentes do sistema operacional do host.
Neste tutorial, você irá instalar e usar a Edição Community (CE) do Docker no Ubuntu 20.04. Você instalará o Docker propriamente dito, trabalhará com contêineres e imagens, e enviará uma imagem para um repositório do Docker.
Pré-requisitos
Para seguir este tutorial, você precisará do seguinte:
Uma conta no Docker Hub se você deseja criar suas próprias imagens e enviá-las para o Docker Hub, como mostrado nos passos 7 e 8.
Passo 1 — Instalando o Docker
O pacote de instalação do Docker disponível no repositório oficial do Ubuntu pode não ser a versão mais recente. Para garantir que tenhamos a versão mais recente, iremos instalar o Docker do repositório oficial do Docker. Para fazer isso, adicionaremos uma nova fonte de pacote, adicionaremos a chave GPG do Docker para garantir que os downloads sejam válidos, e então instalaremos o pacote.
Primeiro, atualize sua lista existente de pacotes:
sudo apt update
Copy
Em seguida, instale alguns pacotes pré-requisito que deixam o apt usar pacotes pelo HTTPS:
Instalando o Docker agora não dá apenas o serviço do Docker (daemon), mas também o utilitário de linha de comando docker, ou o cliente do Docker. Vamos explorar como usar o comando docker mais tarde neste tutorial.
Passo 2 — Executando o Comando Docker Sem Sudo (Opcional)
Por padrão, o comando docker só pode ser executado pelo usuário root ou por um usuário no grupo docker, que é criado automaticamente no processo de instalação do Docker. Se você tentar executar o comando docker sem prefixar ele com o sudo ou sem estar no grupo docker, você terá um resultado como este:
Outputdocker: Cannot connect to the Docker daemon. Is the docker daemon running on this host?.
See 'docker run --help'.
Se você quiser evitar digitar sudo sempre que você executar o comando docker, adicione seu nome de usuário no grupo docker:
sudo usermod -aG docker ${USER}
Copy
Para inscrever o novo membro ao grupo, saia do servidor e logue novamente, ou digite o seguinte:
su - ${USER}
Copy
Você será solicitado a digitar a senha do seu usuário para continuar.
Confirme que seu usuário agora está adicionado ao grupo docker digitando:
id -nG
Copy
Outputsammy sudo docker
Se você precisar adicionar um usuário ao grupo docker com o qual você não está logado, declare esse nome de usuário explicitamente usando:
sudo usermod -aG docker username
Copy
O resto deste artigo supõe que você esteja executando o comando docker como um usuário no grupo docker. Se você escolher não fazer isso, por favor preencha os comandos com sudo.
Vamos explorar o comando docker a seguir.
Passo 3 — Usando o Comando Docker
Usar o docker consiste em passar a ele uma cadeia de opções e comandos seguidos de argumentos. A sintaxe toma esta forma:
docker [option] [command] [arguments]
Copy
Para ver todos os subcomandos disponíveis, digite:
docker
Copy
No Docker 19, a lista completa de subcomandos disponíveis inclui:
Output attach Attach local standard input, output, and error streams to a running container
build Build an image from a Dockerfile
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes to files or directories on a container's filesystem
events Get real time events from the server
exec Run a command in a running container
export Export a container's filesystem as a tar archive
history Show the history of an image
images List images
import Import the contents from a tarball to create a filesystem image
info Display system-wide information
inspect Return low-level information on Docker objects
kill Kill one or more running containers
load Load an image from a tar archive or STDIN
login Log in to a Docker registry
logout Log out from a Docker registry
logs Fetch the logs of a container
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
ps List containers
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
rmi Remove one or more images
run Run a command in a new container
save Save one or more images to a tar archive (streamed to STDOUT by default)
search Search the Docker Hub for images
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
version Show the Docker version information
wait Block until one or more containers stop, then print their exit codes
Para visualizar as opções disponíveis para um comando específico, digite:
docker docker-subcommand --help
Copy
Para visualizar informações de sistema sobre o Docker, use:
docker info
Copy
Vamos explorar alguns desses comandos. Começaremos trabalhando com imagens.
Passo 4 — Trabalhando com Imagens do Docker
Os containers do Docker são construídos com imagens do Docker. Por padrão, o Docker puxa essas imagens do Docker Hub, um registro Docker gerido pelo Docker, a empresa por trás do projeto Docker. Qualquer um pode hospedar suas imagens do Docker no Docker Hub, então a maioria dos aplicativos e distribuições do Linux que você precisará terá imagens hospedadas lá.
Para verificar se você pode acessar e baixar imagens do Docker Hub, digite:
docker run hello-world
Copy
O resultado irá indicar que o Docker está funcionando corretamente:
OutputUnable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
0e03bdcc26d7: Pull complete
Digest: sha256:6a65f928fb91fcfbc963f7aa6d57c8eeb426ad9a20c7ee045538ef34847f44f1
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
...
O Docker inicialmente não conseguiu encontrar a imagem hello-world localmente, então ele baixou a imagem do Docker Hub, que é o repositório padrão. Uma vez baixada a imagem, o Docker criou um container da imagem e executou o aplicativo no container, mostrando a mensagem.
Você pode procurar imagens disponíveis no Docker Hub usando o comando docker com o subcomando search. Por exemplo, para procurar a imagem do Ubuntu, digite:
docker search ubuntu
Copy
O script irá vasculhar o Docker Hub e devolverá uma lista de todas as imagens cujo nome correspondam ao string de pesquisa. Neste caso, o resultado será similar a este:
OutputNAME DESCRIPTION STARS OFFICIAL AUTOMATED
ubuntu Ubuntu is a Debian-based Linux operating sys… 10908 [OK]
dorowu/ubuntu-desktop-lxde-vnc Docker image to provide HTML5 VNC interface … 428 [OK]
rastasheep/ubuntu-sshd Dockerized SSH service, built on top of offi… 244 [OK]
consol/ubuntu-xfce-vnc Ubuntu container with "headless" VNC session… 218 [OK]
ubuntu-upstart Upstart is an event-based replacement for th… 108 [OK]
ansible/ubuntu14.04-ansible Ubuntu 14.04 LTS with
...
Na coluna OFICIAL, o OK indica uma imagem construída e suportada pela empresa por trás do projeto. Uma vez que você tenha identificado a imagem que você gostaria de usar, você pode baixá-la para seu computador usando o subcomando pull.
Execute o comando a seguir para baixar a imagem oficial ubuntu no seu computador:
Após o download de uma imagem, você pode então executar um container usando a imagem baixada com o subcomando run. Como você viu com o exemplo hello-world, caso uma imagem não tenha sido baixada quando o docker for executado com o subcomando run, o cliente do Docker irá primeiro baixar a imagem e então executar um container usando ele.
Para ver as imagens que foram baixadas no seu computador, digite:
docker images
Copy
O resultado se parecerá com o seguinte:
OutputREPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest 1d622ef86b13 3 weeks ago 73.9MB
hello-world latest bf756fb1ae65 4 months ago 13.3kB
Como você verá mais tarde neste tutorial, imagens que você usa para executar containers podem ser modificadas e usadas para gerar novas imagens, que podem então ser enviadas (pushed é o termo técnico) para o Docker Hub ou outros registros do Docker.
Vamos ver como executar containers mais detalhadamente.
Passo 5 — Executando um Container do Docker
O container hello-world que você executou no passo anterior é um exemplo de um container que executa e finaliza após emitir uma mensagem de teste. Os containers podem ser muito mais úteis do que isso, e eles podem ser interativos. Afinal, eles são semelhantes a máquinas virtuais, apenas mais fáceis de usar.
Como um exemplo, vamos executar um container usando a última imagem do Ubuntu. A combinação dos switches -i e -t dá a você um acesso de shell interativo no container:
docker run -it ubuntu
Copy
Seu prompt de comando deve mudar para refletir o fato de você agora estar trabalhando dentro do container e deve assumir esta forma:
Outputroot@d9b100f2f636:/#
Observe o id do container no prompt de comando. Neste exemplo, é d9b100f2f636. Você precisará do ID do container mais tarde para identificar o container quando você quiser removê-lo.
Agora você pode executar qualquer comando dentro do container. Por exemplo, vamos atualizar o banco de dados do pacote dentro do container. Você não precisa prefixar nenhum comando com sudo, porque você está operando dentro do container como o usuário root:
apt update
Copy
Então, instale qualquer aplicativo nele. Vamos instalar o Node.js:
apt install nodejs
Copy
Isso instala o Node.js no container do repositório oficial do Ubuntu. Quando a instalação terminar, verifique se o Node.js está instalado:
node -v
Copy
Você verá o número da versão exibido no seu terminal:
Outputv10.19.0
Qualquer alteração que você faça dentro do container apenas se aplica a esse container.
Para sair do container, digite exit no prompt.
Vamos ver como gerenciar os containers no nosso sistema a seguir.
Passo 6 — Gerenciando os Containers do Docker
Após usar o Docker por um tempo, você terá muitos containers ativos (executando) e inativos no seu computador. Para visualizar os ativos, use:
docker ps
Copy
Você verá um resultado similar ao seguinte:
OutputCONTAINER ID IMAGE COMMAND CREATED
Neste tutorial, você iniciou dois containers; um da imagem hello-world e outro da imagem ubuntu. Ambos os containers já não estão funcionando, mas eles ainda existem no seu sistema.
Para ver todos os containers — ativos e inativos, execute docker ps com o switch -a:
docker ps -a
Copy
Você verá um resultado similar a este:
1c08a7a0d0e4 ubuntu "/bin/bash" 2 minutes ago Exited (0) 8 seconds ago quizzical_mcnulty
a707221a5f6c hello-world "/hello" 6 minutes ago Exited (0) 6 minutes ago youthful_curie
Para ver o último container que você criou, passe o switch -l:
docker ps -l
Copy
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1c08a7a0d0e4 ubuntu "/bin/bash" 2 minutes ago Exited (0) 40 seconds ago quizzical_mcnulty
Copy
Para iniciar um container parado, use o docker start, seguido do ID do container ou nome do container. Vamos iniciar o contêiner baseado no Ubuntu com o ID do 1c08a7a0d0e4:
docker start 1c08a7a0d0e4
Copy
O container irá iniciar e você pode usar o docker ps para ver seu status:
OutputCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1c08a7a0d0e4 ubuntu "/bin/bash" 3 minutes ago Up 5 seconds quizzical_mcnulty
Para parar um container em execução, use o docker stop, seguido do ID ou nome do container. Desta vez, usaremos o nome que o Docker atribuiu ao contêiner, que é quizzical_mcnulty:
docker stop quizzical_mcnulty
Copy
Uma vez que você tenha decidido que você já não precisa mais de um container, remova ele com o comando docker rm, novamente usando o ID do container ou o nome. Use o comando docker ps -a para encontrar o ID ou nome do container associado à imagem hello-world e remova-o.
docker rm youthful_curie
Copy
Você pode iniciar um novo container e dar a ele um nome usando o switch --name. Você também pode usar o switch --rm para criar um container que remove a si mesmo quando ele é parado. Veja o comando docker run help para obter mais informações sobre essas e outras opções.
Os containers podem ser transformados em imagens que você pode usar para criar novos containers. Vamos ver como isso funciona.
Passo 7 —Enviando Alterações em um Container para uma Imagem do Docker
Quando você iniciar uma imagem do Docker, você pode criar, modificar e deletar arquivos assim como você pode com uma máquina virtual. As alterações que você faz apenas se aplicarão a esse container. Você pode iniciá-lo e pará-lo, mas uma vez que você o destruir com o comando docker rm, as alterações serão perdidas para sempre.
Esta seção mostra como salvar o estado de um container como uma nova imagem do Docker.
Após instalar o Node.js dentro do container do Ubuntu, você agora tem um container executando uma imagem, mas o container é diferente da imagem que você usou para criá-lo. Mas você pode querer reutilizar este container Node.js como a base para novas imagens mais tarde.
Então, envie as alterações a uma nova instância de imagem do Docker usando o comando a seguir.
docker commit -m "What you did to the image" -a "Author Name" container_id repository/new_image_name
Copy
O switch -m é para a mensagem de envio que ajuda você e outros a saber quais as alterações que você fez, enquanto -a é usado para especificar o autor. O container_id é aquele que você anotou anteriormente no tutorial quando você iniciou a sessão interativa do Docker. A menos que você tenha criado repositórios adicionais no Docker Hub, repository é normalmente seu nome de usuário do Docker Hub.
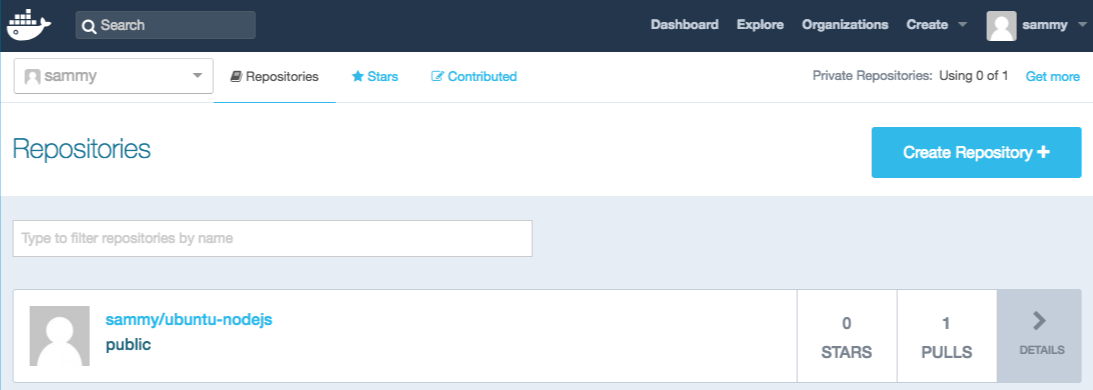
Por exemplo, para o usuário sammy, com o ID do container d9b100f2f636, o comando seria:
docker commit -m "added Node.js" -a "sammy" d9b100f2f636 sammy/ubuntu-nodejs
Copy
Quando você envia uma imagem, a nova imagem é salva localmente no seu computador. Mais tarde neste tutorial, você aprenderá como empurrar uma imagem para um registro do Docker para que outros possam acessá-la.
Listando as imagens do Docker novamente irá mostrar a nova imagem, além da antiga da qual ela foi derivada:
docker images
Copy
Você verá um resultado como esse:
OutputREPOSITORY TAG IMAGE ID CREATED SIZE
sammy/ubuntu-nodejs latest 7c1f35226ca6 7 seconds ago 179MB
...
Neste exemplo, o ubuntu-nodejs é a nova imagem, que foi derivada da imagem ubuntu existente do Docker Hub. A diferença de tamanho reflete as alterações que foram feitas. E neste exemplo, a mudança foi que o NodeJS foi instalado. Então, da próxima vez que você precisar executar um container usando o Ubuntu com o NodeJS pré-instalado, você pode apenas usar a nova imagem.
Você também pode construir Imagens de um Dockerfile, que permite a você automatizar a instalação de software em uma nova imagem. No entanto, isso está fora do âmbito deste tutorial.
Agora vamos compartilhar a nova imagem com outros para que eles possam criar containers a partir dela.
Passo 8 — Empurrando Imagens do Docker para um Repositório do Docker
O próximo passo lógico após criar uma nova imagem de uma imagem existente é compartilhá-la com alguns de seus amigos, todo o mundo no Docker Hub, ou outro registro do Docker que você tenha acesso. Para empurrar uma imagem para o Docker Hub ou qualquer outro registro do Docker, você deve ter uma conta lá.
Para empurrar sua imagem, primeiro logue no Docker Hub.
docker login -u docker-registry-username
Copy
Você será solicitado a autenticar-se usando sua senha do Docker Hub. Se você especificou a senha correta, a autenticação deve ser bem sucedida.
Nota: se seu nome de usuário de registro do Docker for diferente do nome de usuário local que você usou para criar a imagem, você terá que anexar sua imagem com seu nome de usuário de registro. Para o exemplo dado no último passo, você digitaria:
docker tag sammy/ubuntu-nodejs docker-registry-username/ubuntu-nodejs
Copy
Então você pode empurrar sua própria imagem usando:
Modelo de negócio é como se define a dinâmica de como uma empresa se organiza internamente e junto a atores externos para gerar valor a seus clientes e ser reconhecida financeiramente por estes. É tão antigo quanto o primeiro empreendimento de negócio. O Business model canvas de Osterwalder e Pigneur é uma forma de aplicar técnicas de Design Thinking para focalizar no entendimento das necessidades dos clientes (atuais ou futuros) e estruturar os principais elementos que geram valor e são reconhecidos como tal por estes clientes, o que se denomina Proposta de Valor: quais necessidades dos clientes atendemos? Quais dos seus problemas resolvemos com nossos produtos e serviços? Como toda ferramenta de design thinking, seu ciclo de desenvolvimento envolve as etapas de Inspiração, Ideação e Implementação, de forma interativa e incremental, para reduzir os riscos de desenvolvimento de novas configuração de negócio ou de proposta de valor através de desenvolvimento de conhecimento sistemático sobre as necessidades do cliente e sua incorporação em protótipos cada vez mais aderentes a estas necessidades. É uma abordagem baseada em solução de problemas para endereçar as necessidades dos clientes.
Compreende definir quais os segmentos de clientes desejamos atender, qual a proposta de valor para cada um destes segmentos, como a empresa se relaciona com os mesmos, como os recursos internos e de parceiros e atividades estão organizadas para construir e entregar esta proposta de valor, e a dinâmica de custo e receita que o sustenta. Pressupõe entender as necessidades do cliente antes de propor soluções. Também é um processo de inovação sistematizado que busca otimizar uma solução antes de dar passos maiores como investir em uma nova solução ou processo.
Algumas atitudes que contribuem para a aplicação do Design Thinking:
Empatia: Reconhecer que há múltiplas perspectivas de como ver o mundo (por exemplo, os diferentes usuários de um produto ou serviço e como e para que o utilizam, os funcionários que o executam ou o vendem e como isto é realizado) pode ser uma fonte de inspiração para a inovação, para imaginar necessidades latentes ou necessidades atuais não atendidas.
Otimismo: Acreditar que sempre é possível fazer algo de uma forma melhor do que se faz hoje. E não temer experimentar novos caminhos na busca desta melhor solução.
Multidisciplinaridade: Trabalhar de forma colaborativa para incorporar as diferentes visões de mundo e competências de pessoas que estão participando do processo, pois em um mundo complexo é muito difícil que um único design thinker seja capaz de construir só uma solução inovadora, e é muito difícil incorporar a visão do outro diretamente, por conta dos diferentes valores, crenças, experiências individuais envolvidas. Esta é uma das razões de porque o processo de inovação é potencializado pelo emprego do canvas e design thinking: visões relevantes de atores externos ao processo decisório e que muitas vezes passam desapercebidas pelos gestores tem a oportunidade de ser incorporadas (funcionários de diferentes funções e hierarquias, clientes, funcionários e outros stakeholders).
Outra aplicação muito importante do modelo de negócio canvas é a de comunicação. Parte do desafio de implantação de uma boa estratégia é a comunicação da mesma através dos atores da empresa, como gestores e funcionários, seus parceiros de negócio e demais envolvidos. O canvas, sendo um modelo simples e visual potencializa a capacidade de comunicar como a empresa está estrtuurada para gerar valor a seus clientes, e ser remunerada por eles.
O Business Model Canvas foi inicialmente proposto por Alexander Osterwalder[2] baseado no seu trabalho anterior sobre Business Model Ontology.
“Um Modelo de Negócios descreve a lógica de criação, entrega e captura de valor por parte de uma organização.”, Osterwalder.
O BSC é uma metodologia de medição e gestão de desempenho desenvolvida pelos professores da Harvard Business School (HBS) Robert Kaplan e David Norton, em 199, que permite a realização de uma gestão baseada em indicadores, em que o gestor consegue visualizar possíveis oportunidades e gaps internos. Essa ferramenta mapeia os processos de acordo com os objetivos da empresa e divide as metas sob quatro perspectivas: operacional e processos internos, financeira, clientes e, aprendizado e crescimento. É, sem dúvida, uma ferramenta de gestão da empresa que auxilia no planejamento e controle, com maior assertividade de suas metas estratégicas, com o objetivo de medir a evolução da organização por meio de indicadores
Uma das vantagens do BSC é que ele prioriza os projetos e os investimentos sempre com base no orçamento estratégico, evitando rupturas de caixa. Além disso, permite melhor alinhamento entre as equipes, pois todos ficam por dentro do que está acontecendo na empresa e definição e atingimentento das metas propostas.
Estratégia de tecnologia do negócio: os arquitetos precisam ter um entendimento básico do negócio; do contrário não conseguirão dar suporte aos objetivos da organização ou aos objetivos dos clientes. Esses conhecimentos compreendem assuntos financeiros, estratégias de inovação de TI e técnicas de validação, assim como conceitos da indústria, tendências, padrões e compliance (aderência a padrões, regulamentos etc.).
Ambiente de TI: os arquitetos devem ter a “capacidade de verificar a solução e a maturidade organizacional em aspectos funcionais e de procedimentos da empresa”. O ambiente de TI envolve a implementação de elementos relacionados ao processo de desenvolvimento, o gerenciamento de projetos, a utilização de plataformas e frameworks, as mudanças e ativos gerenciais, a governança, além dos testes e controle de qualidade. Por exemplo, arquitetos devem estar alinhados com as tendências de mercado, entender os benefícios e limitações de uma determinada tecnologia, e também conhecer metodologias e tecnologias usadas em um determinado ambiente.
Atributos de qualidade: o atributos de qualidade são mapeados pelo IASA em quatro categorias – qualidades que definem aspectos de usabilidade, aspectos de desenvolvimento como mudanças de requisitos, questões operacionais como performance, além de requisitos de segurança. Tais qualidades são tipicamente requisitos transversais, levando a escolhas importantes, baseadas em limitações de tempo, custo, requisitos e recursos. Wilt enfatiza que os atributos de qualidade devem ser medidos e monitorados constantemente. Devem também ser viáveis: um cliente pode estar interessado em “cinco noves” de disponibilidade, mas pode não querer pagar por tal nível.
Projeto: a capacidade de criar um bom projeto arquitetural é a “principal ferramenta de um arquiteto, ao entregar uma estratégia e um produto para o negócio”. Como Wilt enfatiza, o design não se trata apenas da criação de uma arquitetura; inclui a revisão de todo o projeto. Não é só questão de “belos diagramas”, mas sim de “justificações, razões e ponderações”, quando for necessário tomar decisões. Habilidades necessárias nessa área incluem conhecimentos em técnicas e metodologias de design. E, é claro, arquitetos devem conhecer ferramentas e artefatos de design, como patterns, estilos e views. Para fazer as escolhas corretas sobre o design de um projeto, os arquitetos devem sempre alinhar suas decisões aos requisitos do negócio.
Dinâmica interpessoal: a dinâmcia entre pessoas inclui gerenciar e influenciar pessoas em um contexto de um projeto ou ambiente de TI. Wilt explica que há diversas habilidades necessárias nesse contexto. É necessário lidar com a cultura e com a relação com os clientes, além de lidar com os membros da equipe em um projeto. E embora a maioria dos arquitetos não detenha responsabilidades gerenciais, é necessário que possuam habilidades de liderança e gestão. Além disso, habilidades de negociação e colaboração são requisitos essenciais, assim como escrever e bem e ser capaz de realizar apresentações eficazes.