select kcu.table_schema || '.' ||kcu.table_name as foreign_table,
'>-' as rel,
rel_tco.table_schema || '.' || rel_tco.table_name as primary_table,
string_agg(kcu.column_name, ', ') as fk_columns,
kcu.constraint_name
from information_schema.table_constraints tco
join information_schema.key_column_usage kcu
on tco.constraint_schema = kcu.constraint_schema
and tco.constraint_name = kcu.constraint_name
join information_schema.referential_constraints rco
on tco.constraint_schema = rco.constraint_schema
and tco.constraint_name = rco.constraint_name
join information_schema.table_constraints rel_tco
on rco.unique_constraint_schema = rel_tco.constraint_schema
and rco.unique_constraint_name = rel_tco.constraint_name
where tco.constraint_type = 'FOREIGN KEY'
group by kcu.table_schema,
kcu.table_name,
rel_tco.table_name,
rel_tco.table_schema,
kcu.constraint_name
order by kcu.table_schema,
kcu.table_name;Adiconar HBO Max no Fire Stick TV
Post com procedimento para instalar o HBO Max no Fire Stick TV.
Procedimento
- Entrar no site https://www.amazon.com.br
- Adicionar endereço dos EUA, clicando em Sua Conta / Endereços
- Deixar endereço do Brasil como principal
- Clique em Account & Lists (agora em inglês) escolha Content & Devices
- Clique em Acesse a página Gerenciar seu conteúdo e dispositivos em Amazon.com.
- Clicar em Preferences
- Verifique se Country/Region Settings está em EUA. Se não estiver, clique em Change e selecione o endereço cadastrado nos EUA
- O site deverá mudar para pais EUA
- Digitar HBO Max na caixa de busca
- Clicar em Obtain
- Escolher o Deliver to, Fire Stick que utiliza
- Clicar em Deliver
- Acessar o Fire Stick, então apresentará o HBO Max (clicar em Iniciar agora)
- Voltar para a conta Brasil, no site Amazon, Account & Lists / Content & Devices / Preferences / Country/Region Settings
- Agora é só efetuar o login no HBO Max
The 10 Best Free and Open Source Identity Management Tools
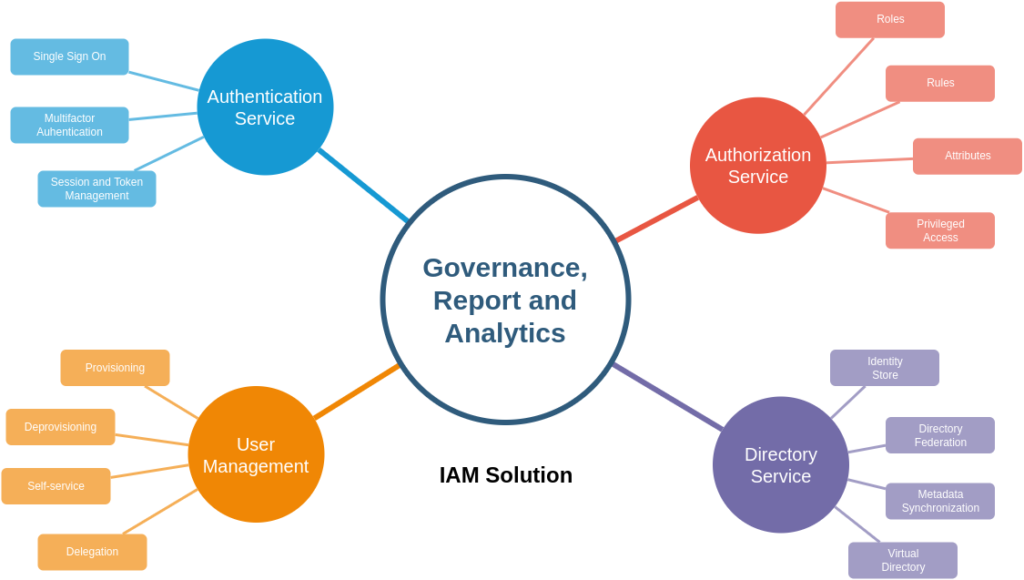
OpenIAM
This stands as perhaps one of the most well-known open-source identity management tools; it features Single Sign-On, user and group management, flexible authentication, and automated provisioning—a major component of identity governance and administration. Moreover, OpenIAM aims to help reduce enterprise operational costs and improve identity audits via a centralized control station. The community version doesn’t enforce a time limit on subscriptions and benefits from community forum support.
Finally, there are different tools for different enterprise identity management needs, including OpenAM and OpenIG.
Check out this open-source access management tool here.
Apache Syncope
The Apache Syncope platform describes itself as an open-source system managing digital identities in enterprise environments; it rarely gets more straightforward. Apache Syncope focuses on providing identity lifecycle management, identity storage, provisioning engines, and access management capabilities. Furthermore, it even offers some monitoring and security capabilities for third-party applications.
Check out this open-source access management tool here.
Shibboleth Consortium
Another of the more widely known identity open-source identity management tools, Shibboleth Consortium offers their Identity Provider; this tool offers web Single Sign-On, authentication, and user data aggregation. Additionally, Shibboleth can enforce your identity management policies on user authentication requests and implement fine-grain controls. It can even scale with your enterprise’s growth right out of the box.
Moreover, the Consortium also provides a service provider and a metadata aggregator as deployable business products.
Check out this open-source access management tool here.
WSO2
Significantly, the WSO2 Identity Service stands as one of the few open-source identity management tools providing CIAM capabilities. For businesses interested in CIAM, WSO2 advertises lower-friction access for customers, data gathering for business intelligence, and streamlined preference management.
Further, the WSO2 Identity Service offers API and microservices security, access control, account management, identity provisioning, identity bridging, and analytics.
Check out this open-source access management tool here.
MidPoint
Midpoint, an open-source IAM tool from Evolveum, seeks to combine identity management and identity governance. Indeed, MidPoint aims to provide scalability, allowing enterprises to grow to accommodate millions of users; it also seeks to offer diverse customization.
Additionally, Midpoint offers an auditing feature—which can even evaluate role catalogs— as well as compliance fulfillment. Its compliance capabilities can even help your enterprise with strict identity regulations such as the EU’s GDPR. The MidPoint solution works for enterprises of all sizes but has features designed for the financial, governmental, and educational industries.
Check out this open-source access management tool here.
Soffid
Like many open-source identity management tools, Soffid offers Single Sign-On and identity management at the enterprise level. In addition, it aims to reduce your IAM support costs and assist with auditing and legal compliance. Critically, Soffid also aims to facilitate mobile device usage through self-service portals.
In the realm of identity governance and administration, Soffid also offers identity provisioning, workflow features, reporting, and a unified directory. It also provides enterprise-wide role management through predefined risk levels.
Check out this open-source access management tool here.
Gluu
Open-source identity management tools aim to keep your cybersecurity platforms together. Thus, Gluu’s name proves remarkably appropriate. Among its features, Gluu offers an authorization server for web & API access management. Also, it provides a directory for identity data storage, authentication middleware for inbound identities, two-factor authentication, and directory integration.
Check out this open-source access management tool here.
Keycloak
Uniquely among the open-source identity management tools listed here, Keycloak positions its design as primarily for applications and services.
The emphasis on third-party application identity security enables your enterprise to monitor and secure third-party programs with little coding. Yet Keycloak also provides out-of-the-box user authentication and federation. Furthermore, it provides standard protocols, centralized management, password policies, and even social login for CIAM needs.
Check out this open-source access management tool here.
FreeIPA
Perhaps a little more esoteric than the other open-source identity management tools listed here, FreeIPA works to manage Linux users particularly. Additionally, it can assist in monitoring and securing digital identity in MIT Kerberos and UNIX networked environments. To this end, FreeIPA provides centralized authentication and authorization through user data storage. Finally, it also offers a web interface and command-line administration tools.
Check out this open-source access management tool here.
Central Authentication Service (CAS)
The last entry on our list of open-source identity management tools, the CAS offers Single Sign-On for the web. However, it offers so much more: an open-source Java server component, support for multiple protocols, diverse integration capabilities, community documentation, and implementation support. CAS also offers session and user authentication process
Check out this open-source access management tool here.
Design Systems
É documento vivo com todos os componentes e propriedades de um produto ou serviço para facilitar a comunicação do time.
Isso beneficia tanto o software como a comunicação, as pessoas, os negócios e as empresas.
Ele pode conter itens básicos como cores, tipografia, marca e até mesmo pedaços de códigos. Além disso, em produtos digitais temos incorporados outros elementos como o Motion Design, que explica como esses elementos devem se comportar quando são animados na interface.
Outro item que pode conter também é Comunicação e Linguagem, explicando como o produto vai se comunicar, que tipos de expressões a marca se permite usar, e isso tem até uma especialidade no mercado que se chama UX Writing (podemos falar mais na próxima).
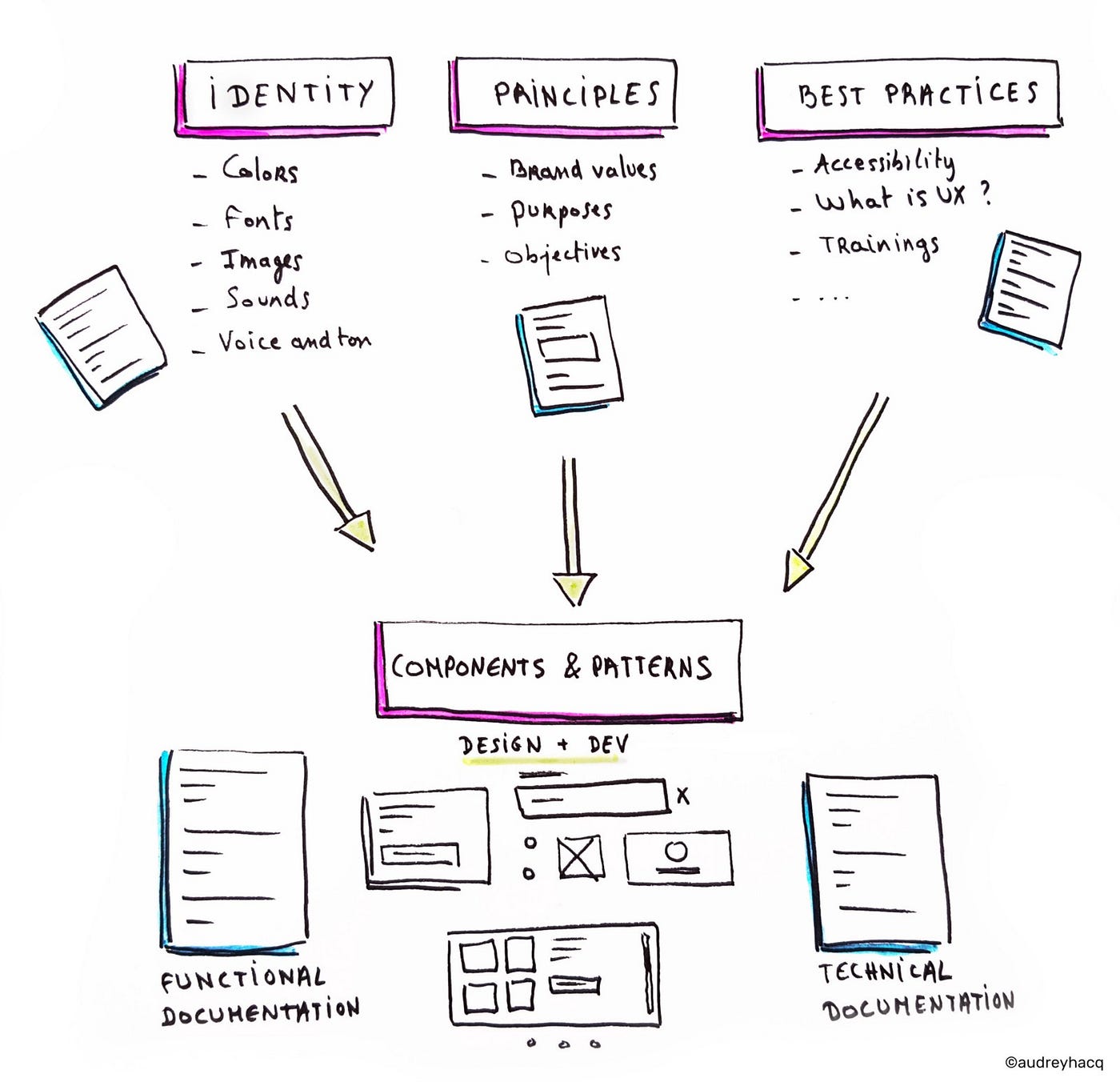
Exemplos
Ferramentas
https://www.figma.com/ – Figma is a vector graphics editor and prototyping tool which is primarily web-based, with additional offline features enabled by desktop applications for macOS and Windows.
https://balsamiq.com/ Wireframing tool
https://webflow.com/blog/prototyping-tools – 14 best prototyping tools
Popular Tools
Popular Tools

JavaScript

GitHub

Python

Git

Node.js

jQuery

Docker

React

Visual Studio Code

HTML5

PHP

Java

Slack

MySQL

Google Analytics

NGINX

Gmail

npm

MongoDB

PostgreSQL

Postman

WordPress

Google Drive

TypeScript

Ubuntu

ES6

Stack Overflow

CloudFlare

Jenkins

AngularJS

GitLab

Jira

Redis

Apache HTTP Server

Google Fonts

Kubernetes

Amazon S3

Vue.js

Amazon EC2

C#

CSS 3

Trello

Google Tag Manager

Font Awesome

Visual Studio

Bitbucket

IntelliJ IDEA

Sass

Firebase

Google Maps

Webpack

Django

Sublime Text

Elasticsearch

jQuery UI

React Native

G Suite

Ruby

VirtualBox
GraphQL

Redux

ExpressJS

Laravel

Heroku

Vim

Android SDK

Dropbox

PyCharm

Android Studio

Spring Boot

Confluence
Kafka

AWS Lambda

Microsoft Azure

Mailchimp

RabbitMQ

ASP.NET

Rails

Kibana

Flask

Amazon CloudFront

Markdown

Docker Compose

Modernizr

Notepad++

New Relic

Ansible

Atom

DigitalOcean

Xcode

ESLint

GitHub Pages

PayPal

Skype

Google Cloud Platform

Swift

Yarn

Babel

Microsoft SQL Server

Google AdSense

Stripe

SQLite

Apache Tomcat

Amazon RDS

MariaDB

Terraform

Grafana

Selenium

gulp

PhpStorm

Microsoft IIS

Debian

Amazon Route 53

Sentry

Gradle

WebStorm

Amazon EC2 Container Service

CentOS

Travis CI

Socket.IO

Flutter

Google Compute Engine

Kotlin

Vagrant

Material Design for Angular

CircleCI
AWS Elastic Load Balancing (ELB)
Logstash

Electron

Amazon CloudWatch

SourceTree

Ionic

Twilio

OpenSSL

Scala

Objective-C

Google App Engine

Varnish

Twilio SendGrid

Asana

Shopify

InVision

HubSpot

Drupal

Amazon SES

Datadog

WooCommerce

Grunt

Animate.css

Symfony

Memcached

Zendesk

Bower

Mailgun

RequireJS

Backbone.js

Slick

Handlebars.js

Intercom
Machine Learning – Tarefas
A seguir estão algumas tarefas de aprendizado de máquina padrão que foram amplamente estudadas:
- Classification: trata-se do problema de atribuir uma categoria a cada item. Por exemplo, a classificação de documentos consiste em atribuir uma categoria, como política, negócios, esportes ou clima a cada documento, enquanto a classificação de imagens consiste em atribuir a cada imagem uma categoria, como carro, trem ou avião. O número de categorias nessas tarefas costuma ser menor do que algumas centenas, mas pode ser muito maior em algumas tarefas difíceis e até mesmo ilimitado, como em OCR, classificação de texto ou reconhecimento de fala.
- Regression: é o problema de prever um valor real para cada item. Exemplos de regressão incluem previsão de valores de estoque ou de variações de variáveis econômicas. Na regressão, a penalidade para uma previsão incorreta depende da magnitude da diferença entre os valores verdadeiros e previstos, em contraste com o problema de classificação, onde normalmente não há noção de proximidade entre as várias categorias.
- Ranking: é o problema de aprender a ordenar os itens de acordo com algum critério. A pesquisa na web, por exemplo, retornar páginas da web relevantes para uma consulta de pesquisa, é o exemplo de classificação canônica. Muitos outros problemas de classificação semelhantes surgem no contexto do projeto de extração de informações ou sistemas de processamento de linguagem natural.
- Clustering: este é o problema de particionar um conjunto de itens em subconjuntos homogêneos. O clustering é freqüentemente usado para analisar conjuntos de dados muito grandes. Por exemplo, no contexto da análise de rede social, os algoritmos de agrupamento tentam identificar comunidades naturais dentro de grandes grupos de pessoas.
- Redução da dimensionalidade ou aprendizado múltiplo: este problema consiste em transformar uma representação inicial de itens em uma representação de dimensão inferior preservando algumas propriedades da representação inicial. Um exemplo comum envolve o pré-processamento de imagens digitais em tarefas de visão computacional.
Os principais objetivos práticos do aprendizado de máquina consistem em gerar previsões precisas para itens invisíveis e projetar algoritmos eficientes e robustos para produzir essas previsões, mesmo para problemas de grande escala.
Para isso, surgem várias questões algorítmicas e teóricas. Algumas questões fundamentais incluem:
- Que famílias de conceitos podem realmente ser aprendidas e em que condições?
- Quão bem esses conceitos podem ser aprendidos computacionalmente?
Machine Learning – Algoritmos
Regressão
É possível prever o valor contínuo de um modelo através do modelo de regressão. Por exemplo, é possível prever os preços dos imóveis em função do tamanho, localização e características da casa. Este é o exemplo mais simples de compreensão da regressão. A regressão é uma técnica supervisionada.
Regressão Lasso
Esta técnica é um tipo de regressão linear e ajuda a diminuir a limitação do modelo. Os valores dos dados encolhem para o centro ou média para evitar o sobre-ajustamento dos dados. Regressão Lasso pode eliminar as variáveis inúteis da equação. Este tipo de regressão é melhor do que a regressão de Ridge e ajuda a reduzir as Variâncias num modelo de aprendizagem da máquina que contém muitas Variâncias.
KNN – K-Nearest Neighbor
Em estatística, o algoritmo de vizinhos k-mais próximos é um método de classificação não paramétrico desenvolvido pela primeira vez por Evelyn Fix e Joseph Hodges em 1951, e posteriormente expandido por Thomas Cover. É usado para classificação e regressão.
Links
https://minerandodados.com.br/machine-learning-na-pratica-knn-python/
https://portaldatascience.com/o-algoritmo-k-nearest-neighbors-knn-em-machine-learning/
Redes Bayesianas / Bayes Theorem / Bayesian Methods
O algoritmo “Naive Bayes” é um classificador probabilístico muito utilizado em machine learning. Baseado no “Teorema de Bayes”, o modelo foi criado por um matemático inglês, e também ministro presibiteriano, chamado Thomas Bayes (1701 – 1761) para tentar provar a existência de Deus.
Random Forest
Baseia-se justamente em um dos algoritmos mais básicos da área de mineração de dados: as árvores de decisão.
K-Means
K-Means é um algoritmo de clusterização (ou agrupamento) disponível na biblioteca Scikit-Learn.
É um algoritmo de aprendizado não supervisionado (ou seja, que não precisa de inputs de confirmação externos) que avalia e clusteriza os dados de acordo com suas características.
PCA – Principal Component Analysis
O PCA é uma técnica estabelecida de aprendizado de máquina. É frequentemente usado na análise de dados exploratória porque revela a estrutura interna dos dados e explica a variação nos dados.
Boosting
No aprendizado de máquina, Boosting é um meta-algoritmo de conjunto para reduzir principalmente o viés e também a variação no aprendizado supervisionado. Baseia-se justamente em um dos algoritmos mais básicos da área de mineração de dados: as árvores de decisão.
Redes Neurais
Redes neurais são sistemas de computação com nós interconectados que funcionam como os neurônios do cérebro humano. Usando algoritmos, elas podem reconhecer padrões escondidos e correlações em dados brutos, agrupá-los e classificá-los, e – com o tempo – aprender e melhorar continuamente.
Hill Climbing
- Segue apenas um sentido, explorando a “vizinhança”
- Não garante obter o Global Optima
- Existem muitas variações, principalmente incluindo elementos não determinísticos no algoritmo
Breadth First Search
Capaz de retornar de uma vizinhança em busca de uma solução melhor (backtracing)
Depth-first search
Explora uma “vizinhança”, retornando e tentando outras ramificações
Best First Search
Usa heurística para avaliar o valor de cada nó
Sua performance depende da heurística
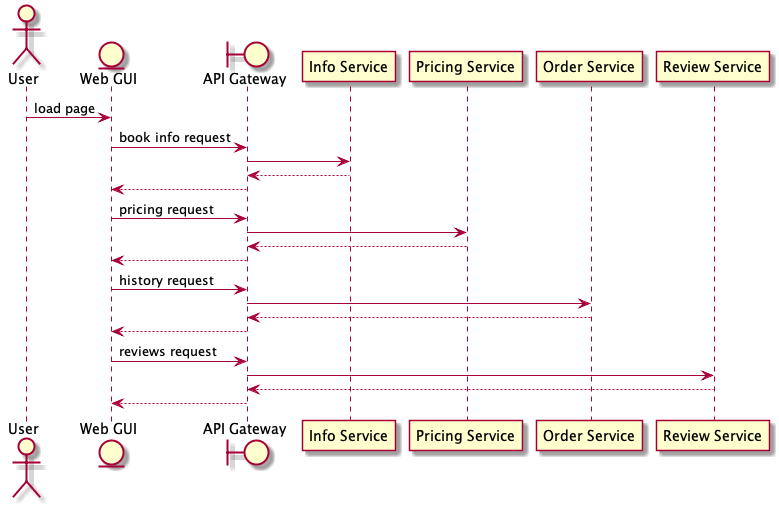
Benefícios do API Gateway
Aqui, pretendo levantar os benefícios na utilização de um API Gateway.
Benefícios
- Evita expor a API para cada micro-serviço
- Não havendo exposição da API consumidora, reduzindo a superfície de ataque potencial
- Abstração dos micro-serviços, tanto na parte de endpoints quanto payload
- Atua como Load Balancer
- Pode gerenciar Black List e White List
- Atua na Autenticação e Autorização de APIs
- Permite a transformação de formatos, manipulação de estruturas e validações de campos
- Pode compor dados, integrando várias APIs (veja o pattern API Composition)
- Pode atuar como BFF – Backend For Frontend, simplificando o payload e reduzindo tráfego
- Permite controle de requisições como Rate Limit
- Mitiga riscos de OWASP
- Permite controle de chamadas, gerando relatórios, importantes para monetização da API
- Monitora e faz tracing das chamadas



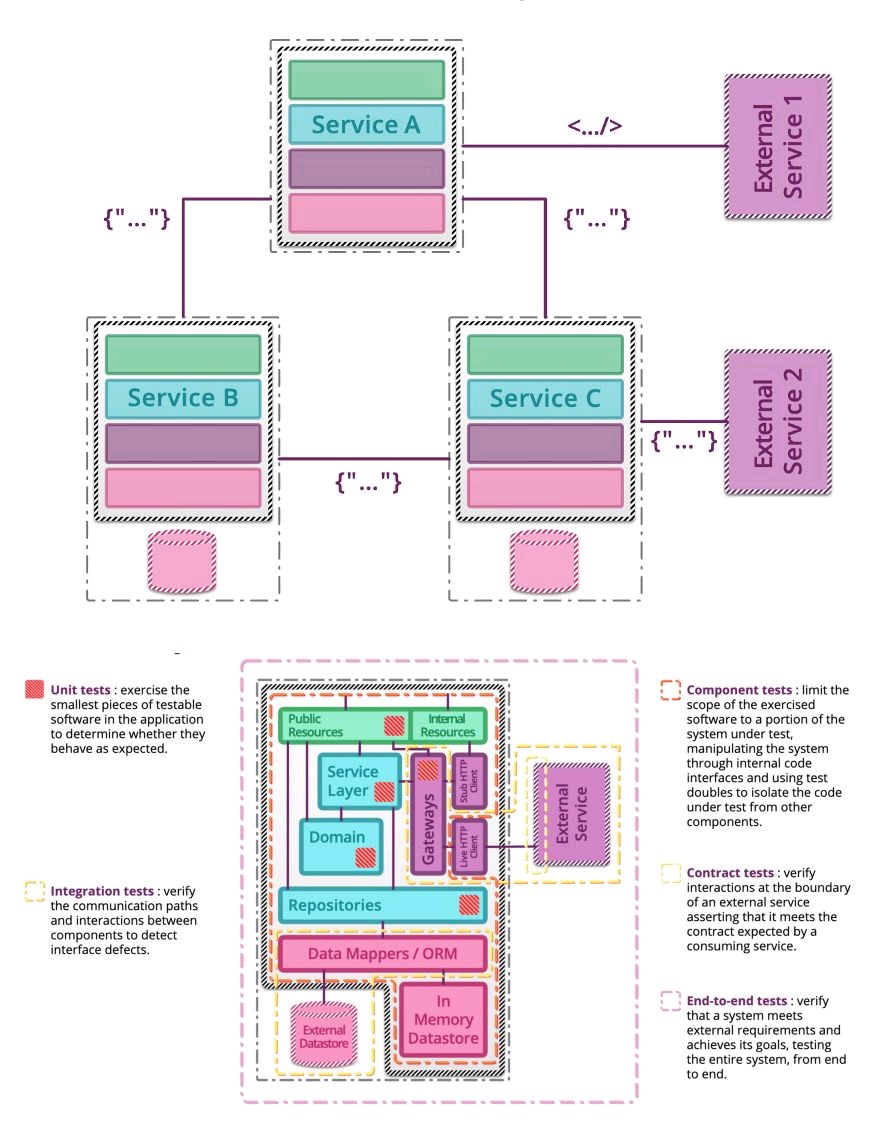
Software testing types
Gerência de TI
Prepare-se! Chegou a hora de você testar o conhecimento adquirido nesta disciplina. A Avaliação Virtual (AV) é composta por questões objetivas e corresponde a 100% da média final. Você tem até cinco tentativas para “Enviar” as questões, que são automaticamente corrigidas. Você pode responder as questões consultando o material de estudos, mas lembre-se de cumprir o prazo estabelecido. Boa prova!
Arquivos e Links