Post para mapear os principais testes de código.
Coding Interview
| Uber S1 |
Solution
| Educative S1 S2 S3 |
A contribuição da IA vem em duas formas principais: generativa e preditiva. No artigo a seguir, exploraremos as distinções entre IA generativa e preditiva, mostrando como cada tipo está moldando o futuro da resolução de problemas em vários campos.
IA generativa é um tipo de inteligência artificial que pode criar novas informações, como texto, imagens, música ou até mesmo vídeos, com base nos dados em que foi treinada. Em vez de apenas analisar ou processar informações existentes, ela gera novas ideias e resultados.
Imagine que você peça a um modelo de IA generativa como o ChatGPT para escrever uma história curta sobre um dragão e uma princesa. A IA usa o que sabe sobre narrativa, personagens e tramas para criar uma história completamente nova. Ela não apenas copia histórias existentes; ela combina ideias de maneiras criativas para gerar algo único.
Em uma aplicação prática, a IA generativa pode ser usada na arte. Por exemplo, um modelo de IA pode se inspirar em milhares de pinturas e criar uma obra de arte totalmente nova que nunca foi vista antes, misturando estilos e técnicas de maneiras inovadoras.
IA preditiva se refere à tecnologia que usa dados, algoritmos e aprendizado de máquina para prever resultados futuros com base em dados históricos. Ela analisa padrões e tendências para fazer suposições fundamentadas sobre o que pode acontecer a seguir.
Por exemplo, imagine uma loja que quer saber quantos sorvetes estocar para o verão. A loja analisa dados de vendas de verões anteriores, incluindo fatores como temperatura, eventos locais e promoções. Usando IA preditiva, a loja analisa esses dados para encontrar padrões, como como dias quentes levam a mais vendas de sorvete.
A IA prevê que em dias em que a temperatura estiver acima de 30°C, as vendas de sorvete aumentarão em 50%. Com base nessa previsão, a loja decide estocar mais sorvete em dias ensolarados, garantindo que eles tenham o suficiente para os clientes sem estocar demais.
Embora ambos os tipos de IA sejam poderosos, eles atendem a propósitos diferentes. Vamos entender as principais diferenças.
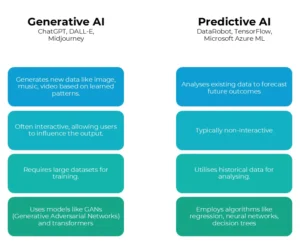
Enquanto a IA generativa atrai atenção por seus novos recursos na criação de conteúdo, a IA preditiva continua sendo uma ferramenta poderosa para melhorar a eficiência operacional e gerar economias substanciais de custos em processos de negócios estabelecidos.
A IA preditiva aprimora as operações existentes, levando a melhorias significativas de eficiência. Por exemplo, a UPS, empresa de serviços globais de remessa e logística, economiza US$ 35 milhões anualmente ao otimizar rotas de entrega, enquanto os bancos podem economizar milhões ao prever com precisão transações fraudulentas. Essa tecnologia tem um histórico comprovado de entrega de altos retornos por meio de processos sistemáticos que as empresas já estabeleceram.
A IA preditiva geralmente funciona sem intervenção humana, tomando decisões instantâneas com base na análise de dados. Por exemplo, ela pode aprovar automaticamente transações de cartão de crédito ou otimizar posicionamentos de anúncios em sites. Em contraste, a IA generativa geralmente requer supervisão humana, pois suas saídas precisam ser revisadas quanto à precisão e qualidade, tornando-a menos adequada para tarefas totalmente automatizadas.
Os modelos de IA preditiva são tipicamente muito mais leves e menos intensivos em recursos em comparação aos modelos complexos usados em IA generativa. Enquanto os modelos generativos podem consistir em centenas de bilhões de parâmetros e exigir dados extensos para treinamento, os modelos preditivos geralmente precisam de apenas alguns milhares de parâmetros, tornando-os mais fáceis e baratos de implantar.
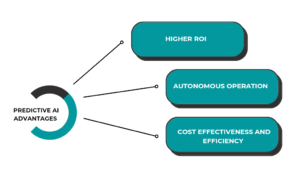
A IA generativa e a IA preditiva atendem a propósitos e funções diferentes, fazendo com que uma não seja uma substituição direta da outra. Embora a IA generativa possa aprimorar modelos preditivos (por exemplo, gerando cenários ou simulações com base em previsões), ela não pode substituir totalmente as capacidades analíticas da IA preditiva. Cada uma tem seus pontos fortes e aplicações, e elas podem se complementar em vários campos, mas não são intercambiáveis.
O futuro está em investir corretamente para alavancar a parceria entre IA preditiva e generativa. A IA generativa se destaca na criação de conteúdo e soluções inovadoras, enquanto a IA preditiva se concentra na previsão de tendências e otimização de decisões. Juntas, elas aprimoram as operações comerciais, levando a valor mensurável e ROI aprimorado.
Por exemplo, na área da saúde, a IA preditiva prevê resultados de pacientes, permitindo intervenções oportunas, enquanto a IA generativa pode ajudar a criar planos de tratamento personalizados. Em finanças, a IA preditiva analisa dados de mercado para aprimorar estratégias de negociação, enquanto a IA generativa pode auxiliar na simulação de vários cenários de investimento.
Essa sinergia entre IA generativa e preditiva não apenas simplifica processos e aumenta a lucratividade, mas também promove o engajamento do cliente por meio de experiências personalizadas. As empresas que aproveitam os pontos fortes de ambas as tecnologias podem impulsionar eficiências operacionais, responder às necessidades do mercado rapidamente e manter uma vantagem competitiva.
No cenário em evolução da IA, a integração estratégica de capacidades generativas e preditivas é a chave para desbloquear todo o seu potencial, garantindo que as empresas obtenham retornos imediatos enquanto se preparam para um futuro definido pela inovação da IA.
Este post documenta comandos e fontes do curso da Udemy – Curso de Python 3 do básico ao avançado
Install Python
sudo apt update -y sudo apt upgrade -y sudo apt install git curl build-essential -y sudo apt install gcc make default-libmysqlclient-dev libssl-dev -y sudo apt install python3.10-full python3.10-dev -y
Ativar ambiente virtual
Fontes
https://gist.github.com/luizomf/8623264cbf69cd2619bcdee258628f41
https://gist.github.com/luizomf/688c8a48fe007829c120818138ac2317
Documentação do Python: Ex: https://docs.python.org/3.13/library/string.html
Uma API canônica é uma interface de programação de aplicação (API) projetada para ser a representação oficial, ou “fonte única da verdade”, de um sistema ou domínio. O conceito de canônica refere-se a algo que segue um padrão autorizado ou é a forma mais pura e completa de algo.
No contexto de APIs, isso significa que a API canônica é a interface principal, geralmente abstrata e agnóstica à tecnologia, que expõe o modelo de domínio de maneira consistente e clara para consumo por diferentes partes do sistema ou por sistemas externos.
Em um sistema de e-commerce com um domínio que inclui clientes, pedidos e produtos, uma API canônica exporia operações que permitem a criação de pedidos, consulta de produtos, gerenciamento de clientes, etc., de forma que todos os serviços relacionados interajam com esses dados e regras de uma maneira consistente.
/orders/create)/products/{id})/customers/{id}/update)Essencialmente, a API canônica é um ponto de acesso estruturado e padronizado para todo o domínio de um sistema, garantindo consistência e governança.
Este procedimento resolve o problema de placa de som não ser reconhecida, típico problema “Saída Fictícia”.
Você precisa adicionar essas duas linhas no final de /etc/modprobe.d/alsa-base.conf
opções snd-hda-intel model=auto
blacklist snd_soc_avs
É exatamente isso que ele está fazendo:
opções snd-hda-intel model=auto:
Esta linha configura o comportamento do driver snd-hda-intel, responsável por manipular áudio de alta definição (geralmente associado a placas de som Intel) no Linux.
A opção model=auto permite que o driver detecte automaticamente o codec de áudio usado pelo seu hardware e selecione as configurações de modelo apropriadas para ele. Isso é útil quando a configuração padrão não se alinha perfeitamente com os recursos do hardware, potencialmente resolvendo problemas em que certas funcionalidades de alto-falante ou microfone não são reconhecidas corretamente.
lista negra snd_soc_avs:
Esta linha impede que o módulo snd_soc_avs seja carregado pelo kernel Linux. snd_soc_avs significa Sound Open Firmware Audio DSP para plataformas Intel com sincronização de áudio e vídeo, que pode fazer parte do tratamento de som em sistemas Intel modernos.
Ao colocar este módulo na lista negra, você evita que ele interfira com o driver principal snd-hda-intel. Parece que, no seu caso, snd_soc_avs estava causando conflitos ou não era totalmente compatível com sua configuração de áudio específica, levando aos problemas que você estava enfrentando. Ao impedi-lo de carregar, você permite que o sistema dependa de outros módulos, talvez mais compatíveis, para lidar com o processamento de áudio.
Fonte: https://askubuntu.com/questions/1511648/audio-not-working-ubuntu-24-04
Me escreva um artigo sobre primeiros passos no Docker, em tom de conversa com uma criança de 10 anos. Agora, use os itens em {RESUMO) para o
{ROTEIRO} seguindo as {REGRAS}
{RESUMO}
[Autoridade]: Felipe, um desenvolvedor Fullstack
[Avatar]: Desenvolvedores Júniors
[Problema]: Como instalar o Docker
{ROTEIRO}
Olá eu sou [Autoridade] e vou ajudar o [Avatar]
Hoje vamos resolver o [Problema]
{REGRAS}
> Siga o {ROTEIRO) acima e substitua os elementos entre [ ]
por aqueles listados em {RESUMO} acima.
> Mantenha o tom e ritmo, mas reescreva as palavras em {ROTEIRO} para que seja diferente do original, expandindo ou mudando conforme necessário.
> Use analogias simples e hipérboles
Me [FUNÇÃO] um [TIPO DE TEXTO] sobre [assunto] nesse [estilo]
FTAE
Função: (escreva/resuma/traduza/crie tópicos)
Tipo de texto: (roteiro/post para blog/artigo/poema/postagem para instagram)
assunto: (I.A, futebol, música, filme... etc)
estilo: (personalidade, escritor, filósofo)
Me [crie tópicos] um [um artigo] sobre [macarrão]
Me [escreva] um [TEXTO] sobre [INTELIGÊNCIA ARTIFICIAL]
Escreva para quem aquela comunicação deve ser direcionada para calibrar o entendimento e naturalidade da resposta
Tom de voz: me explique como se fosse (para uma criança de 10 anos, de um jeito mais sênior
Exemplos:
Me escreva em formato de carrossel do instagram uma postagem sobre programação com os princpais me explicando o que é DOCKER em um estilo informal e descontraído como se tivesse sido postado por um influencer de tecnologia, explique como se fosse para uma criança de 10 anos
Me escreva em formato de carrossel do instagram uma postagem sobre programação com os princpais me explicando o que é DOCKER em um estilo informal e descontraído como se tivesse sido postado por um influencer de tecnologia, explique com um tom de voz mais sênior
Best side hustles
Act as financial advisor. Provide a list of the most priftable side hustles to start in 2024. Include detailson potential earnings, required skills, and initial investment needed.
Hig-paying side jobs
Act as a career consultant. Suggest a list of high-paying side jobs to apply for in 2024. Include information on the average pay, necessary qualifications and how to get started.
Business ideas
Act as an entrepreneur coach. Provide a list of profitable business ideas I can start with an initial investment of [AMOUNT]. Include steps to get started, potential profit margins and tips for success.
SWOT analysis
Act as a personal development coatch. help me coduct a SWOT analysis of myself. Guide me through iidentifying my strengths, weaknesses, opportunities and threats, and suggest strategies to leverage this analysis for financial success.
Passive income
Act as a financial strategist. Suggest ways to Create a passive income stream. Provide a list of potential passive income sources, Such as rental properties, dividend stocks, or online businesses, an explain how to start with each.
Best skills to learn
Act as a career coach, Recommend skills to learn in 2024 that can significantly increase my earning potential, Include Informatlon on how to acquire these skills, potentlal job and business opportunities, and expected salary increases.
Prompt: Act as financial advisor. Provide a list of the most priftable side hustles to start in 2024. Include detailson potential earnings, required skills, and initial investment needed.
Here’s a list of some of the most profitable side hustles for 2024, along with details on potential earnings, required skills, and initial investment:
Each of these side hustles varies in terms of earnings potential, skill requirements, and initial investment. The key is finding one that aligns with your skills, interests, and financial goals.
Q: Como promover a exponencialidade de inovação para uma empresa?
Promover a exponencialidade da inovação em uma empresa exige uma abordagem sistemática e multifacetada. Abaixo estão algumas estratégias-chave para fomentar um ambiente que permita à inovação crescer de forma exponencial:
Essas abordagens, quando aplicadas de maneira integrada, ajudam a criar uma cultura e uma estrutura que permitem que a inovação floresça de forma exponencial, gerando um impacto significativo no crescimento da empresa.
Olá!
Eu quero te mostrar um truque bem poderoso de produtividade do chat PT na era do chat PT Plus e do chatPT e que muita gente não conhece.
É que tem muito curso por aí que diz ser um curso avançado e que nem aborda o recurso de personalizar o chat para você, ou seja, dizer para o chat exatamente como você quer que ele funcione para você.
Para o seu tipo de trabalho, para a forma de uso que você vai usar com mais frequência.
E como é que você faz isso?
E para personalizar o chat eu tenho duas opções.
Aqui repara que está inibido porque eu desabilitei aqui, mas já já vou te mostrar o que que é isso?
Para que que isso serve?
Então vamos lá.
Primeira coisa que está aqui em cima O que você gostaria que o PT soubesse a seu respeito para fornecer
melhores respostas?
Ou seja, o que você faz?
Qual seu tipo de trabalho?
Qual o seu estilo de produção?
Ele quer saber sobre você?
Você inclusive pode informar o seu nome e ele vai usar o seu nome caso você queira produzir, por exemplo,
um contrato ou algum documento que tenha o seu nome, CPF, etc.
Olha só o que está aqui escrito para mim.
Eu cliquei aqui e personalizei escrevendo o seguinte.
Sou professor do Ensino Médio Superior, especialista no assunto definido pelo prompt, especialista
no assunto definido pelo prompt.
O que quer dizer isso?
Paulo, quando eu executar um prompt ou um comando, seja quando eu enviar uma mensagem ao GPT, ele
vai analisar essa mensagem.
Vai falar Hum.
Isso aqui diz respeito à internet.
Então o chat PT vai entender que eu sou um especialista em internet.
Hum, isso aqui diz respeito a mecânica de automóvel.
Ah, então essa pessoa.
O Paulo é especialista em mecânica de automóvel Por que isso é importante?
Porque quando eu mandar um comando para ele, ele vai saber exatamente qual é o escopo do que se trata.
Vou dar um exemplo bobo.
Imagine que eu vou falar sobre manga e eu sou um alfaiate.
Eu faço roupas.
É claro que não vai ser a fruta manga.
Vai ser a manga da minha camisa.
Contexto é um assunto que eu falo durante o curso, em vários momentos, extremamente poderoso.
Então, quando eu escrevo isso aqui, eu estou fazendo com que o chat PT analise a minha resposta e
defina o contexto em cima da especialidade do meu comando.
Logo depois eu escrevo isso aqui.
Escrevo de forma detalhada e abrangente.
Eu gosto de escrever de forma detalhada e abrangente.
Isso faz com que o chat PT não seja muito resumido nas respostas.
Meu público tem faixa etária de 14 a 20 anos.
No caso, eu estou preparando, por exemplo, conteúdo para meus alunos.
Busco explicar meu conteúdo com analogias e exemplos.
É bom ensinar para os alunos através de analogia.
Exemplos.
Escrevo em tom amigável e agradável.
E aqui está.
Eu posso escrever até 1500 caracteres.
Eu coloquei somente isso para você entender o contexto do que é instrução personalizada é agora que
tem o poder.
É o truque que muita gente não conhece como o chat PT deveria responder.
E aqui eu uso um truque bastante interessante.
Aqui o chat PT indica que você pode dizer que você quer que ele responda de forma mais formal e formal.
Respostas longas curtas Como é que ele deve se dirigir a você?
E assim vai.
Só que eu uso esse recurso além desta forma, de uma outra forma, que é ensinando o chat PT a usar
atalhos usando a barra.
Ou seja, eu digo aqui como ele deve responder usando comandos.
Ou seja, eu crio atalhos de mensagens.
Agora, o que eu quero te mostrar também é o seguinte isso aqui é uma brincadeira.
Por exemplo, se eu botar a barra H, ele vai me informar a hora atual, barra TI.
Ele vai traduzir o texto que eu escrevi anteriormente para inglês e traduz para português.
Mas o que eu quero te mostrar aqui de interessante é o seguinte este comando aqui, que é um prompt
longo, eu uso para ensinar ele a escrever adequadamente artigos para mim.
Eu vou te mostrar como é que funciona isso.
Já, já.
Primeiro eu vou desligar isso daqui.
Eu quero dizer que essa instrução personalizada ele está aqui no curso.
Na segunda aula, se você clicar aqui, você clica em Instruções personalizadas.
Vai abrir aqui um documento.
Um arquivo texto é um arquivo texto puro.
Você clica aqui em Abrir e aqui está a versão três desse texto.
O que você gostaria que soubesse sobre você e que é 1/1?
E aqui eu já não sou mais o professor, no caso aqui.
Esse contexto que eu criei aqui é para o escritor.
Então eu vou copiar inclusive isso aqui para substituir lá naquela outra opção.
E aqui está tudo o que está escrito lá no prompt.
Então você não precisa tentar achar essa informação.
Você pode simplesmente clicar nesse arquivo, baixar, copiar a informação para dentro do GPT.
Eu vou fazer exatamente isso agora eu vou vir aqui, vou tirar aqui meu outro navegador, vou vir aqui
em cima, vou clicar em Personalizar o chat GPT, vou ativar aqui e vou substituir isso aqui para que
a mensagem Atue como redator de conteúdo especialista no assunto definido pelo prompt.
Você sempre escreve de forma detalhada e abrangente, tentando escrever pelo -1500 palavras.
Esta é a minha instrução personalizada para escrever artigos.
Eu escrevo muito conteúdo, artigos para sites, artigos para as minhas aulas.
Então, essa é a minha estrutura e o meu truque para escrever conteúdo que depois vira apresentação,
que depois vira conteúdo para site e assim vai.
Eu vou desabilitar aqui por enquanto e vou clicar em Salvar.
E agora eu vou te mostrar o poder da instrução personalizada.
Primeiro não usando ela e depois usando ela.
Eu vou esconder aqui essa telinha e vou escrever aqui.
Crie um artigo sobre produtividade pessoal.
Obviamente, o assunto produtividade pessoal é um assunto muito extenso, inclusive eu tenho curso sobre
produtividade aqui na plataforma.
Mas vamos ver o que que ele vai responder para mim.
O chip vai começar a processar as informações e aqui ele começa a escrever.
Pronto, Ele escreveu o texto.
Eu vou clicar aqui para copiar esse texto.
Se você quiser também, pode clicar aqui para ouvir o texto sendo narrado em voz alta e vamos ver quantos
caracteres tem esse artigo e para ele ficou bem interessante.
Ele organizou em tópicos um, dois, três.
Eu não vou ler esse conteúdo, mas eu vou colocar aqui dentro desse site para contar o número de caracteres.
Então repare que ele criou um artigo de 603 palavras com 4130 caracteres.
Esses símbolos que ele colocou aqui são o que nós chamamos de Markdown.
Ele transforma esses elementos nessa simbologia ali para indicar que é título, subtítulo, subtítulo
do subtítulo e assim vai.
Então nós temos aqui 4130 caracteres, 603 palavras.
E agora vamos fazer esse mesmo prompt.
Eu vou vir aqui em cima.
Vou pegar aqui o prompt, vou apertar Ctrl C para copiar para mim.
Vou clicar aqui para criar um novo chat e vou vir aqui agora e vou vir em Personalizar Chat e vou ativar
para novos chats.
Vou clicar em Salvar.
Eu vou inclusive criar de novo.
Aqui eu vou clicar em Criar novo novamente.
Para ter certeza que ele vai usar minha instrução personalizada, vou jogar aqui o prompt.
Criei um artigo sobre produtividade pessoal e vamos ver agora a diferença em termos de resposta.
Pronto, artigo foi gerado.
Olha o tamanho desse artigo.
Ele colocou referências porque está na instrução personalizada.
Eu vou te mostrar aqui.
Olha, aqui está o arquivo da instrução personalizada.
Aqui eu peço para ele colocar perguntas, pontos relevantes e eu peço aqui que ele indique três livros
como bibliografia.
Escreva usando as normas da ABNT.
Então ele seguiu e colocou aqui três livros como bibliografia e o texto é bem, bem maior.
Como você pode observar aqui, é bem maior.
Quer ver como é tão maior?
Olha só, eu vou ver aqui.
Ah, ele não acabou.
Por que que não acabou?
Porque ele está perguntando se eu quero criar uma apresentação baseada no artigo.
Lembra que eu falei que eu sou professor universitário?
Eu crio muito conteúdo de aulas usando o site CPT.
Ele criou o texto, eu vou analisar o texto, vou ver se tá legal.
Eu posso pedir para ele automaticamente Criar a estrutura de uma apresentação para mim.
Mas vou deixar isso para depois.
Vou clicar aqui simplesmente para copiar.
Vou voltar aqui para nossa página que tinha 4130 caracteres para o prompt comum prompt que a maioria
das pessoas usam.
Ou seja, uma forma muito simples e este aqui é o resultado.
Copiei o artigo todo.
Aqui eu tenho um artigo que é mais do dobro em termos de caracteres e mais do dobro em termos de palavras.
1261 palavras.
E aqui na tela vai aparecer para você como era o tamanho anterior, tanto de palavras quanto de caracteres.
Repara que eu usei uma instrução personalizada e eu criei um conteúdo muito maior.
E não é só isso.
Aqui na instrução Personalizada eu peço para ele criar uma apresentação baseada deste artigo.
Então, o que eu vou fazer?
Eu vou simplesmente escrever, sim.
E olha que ele vai fazer.
Ele vai pegar o conteúdo e vai organizar em slides.
Olha.
Slide um Introdução Slide dois Slide três Slide quatro Slide cinco.
Seis Até o slide 12 de referências e agora ele coloca aqui o índice para o meu slide dois, que é o
meu slide de estrutura e aqui está o conteúdo de cada slide.
Prontinho!
Aliás, ele continuou criando.
Eu acho que eu pensei que ele fosse ficar só idoso, mas ele continua criando e não para de criar.
Esse é o poder da versão mais atual do CPT, que é o que a gente está usando.
Olha, já tá no slide 28, pediu para eu continuar gerando.
Acontece isso de tempos em tempos.
Eu vou clicar aqui para continuar gerando e ele vai continuar criando meu slide.
Repara que o único prompt agora gera esta quantidade de conteúdo e isso você pode fazer para qualquer
coisa.
Basta você modificar a sua instrução personalizada.
Ele vai gerar esse conteúdo para você da forma que você quiser.
Então é isso.
Este é o truque de produtividade extremamente poderoso que eu queria mostrar para você.
Infelizmente, muita gente não conhece isso.
Eu vejo muita gente dizendo que tem cursos completos de chat, mas não mostra esse recurso tão importante.
E lembre se, você pode customizar esse texto à vontade, mas faltou te mostrar um truque importante,
que é o seguinte.
Olha só, eu vou clicar aqui para criar um novo chat e agora eu não preciso escrever.
Crie um artigo sobre produtividade pessoal.
Agora eu posso simplesmente fazer isso aqui.
Ah, e colocar isso aqui, ó.
Produtividade pessoal.
E você vai entender como que é para escrever um artigo.
Eu vou parar aqui porque senão vai demorar um tempão.
Vou mostrar para você os outros comandos.
Lembra que eu coloquei aqui barra T e barra P?
Olha o que eu vou fazer.
Eu vou voltar naquela conversa anterior e vou fazer o seguinte barra t i.
Somente isso.
Barra ti.
E olha só, ele vai traduzir todo o conteúdo, todo o artigo, toda a última resposta para inglês.
E isso acontece porque eu disse aqui para ele fazer isso.
Tá vendo?
Se eu usar o comando p ele vai traduzir todo o conteúdo para o português.
Se você quiser que traduza para português, chinês, italiano para o que você quiser.
Você pode usar esse tipo de sistema de atalhos.
Este é um truque extremamente poderoso.
Criar um prompt como esse que eu coloquei aqui, que escreve o conteúdo.
Isso você vai ver aqui dentro do curso, em mais detalhes em outras seções.
Mas saber usar o sistema de atalhos.
Pouca gente não conhece, ou seja, ensinar o chat a usar atalhos, pouca gente conhece e agora você
conhece.
Você pode criar todos os atalhos que você quiser.
E se você criou algum atalho interessante, compartilha aqui na aula, vai na área de perguntas e respostas
do curso e coloca lá.
E por último, eu vou te mostrar o H.
O que é o H?
H.
Informa que hoje é domingo, 16 de julho de 2024.
São 13h12.
Tá quase na hora de almoçar.
É isso.
Espero que você tenha gostado desse truque de produtividade.
Clicando aqui Personalizar Chat Você pode fazer o chat, responder da forma que você quiser, sempre
sem ter que escrever prompt gigantescos.
Espero que você tenha gostado desse truque e até a próxima aula.