Prompt
Atue como Arquiteto de Solução, que tem por objetivo detalhar a arquitetura de um sistema de EDMS, Electronic Document Management System. Utilize as melhores práticas dessa solução, aplicando conceito de micro-serviços orquestrados pelo orquestrador EDMS. Apresente os conceitos e papéis de cada micro-serviços, como:
- Storage
- OCR
- Data store (basic data)
- Metadata
- Machine Learning (objective to detect type of document and entity)
- Permission
- Audit and Logging
- Workflow and Approval
- Lifecycle of document
Identifique conceitos que achar importante e que não está na lista acima.
Answer
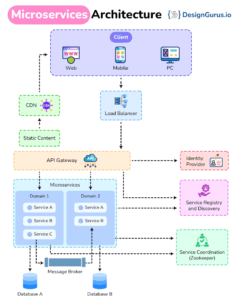
Visão geral da solução EDMS baseada em microserviços
A seguir apresento uma arquitetura de referência para um EDMS (Electronic Document Management System) moderno, baseado em microserviços e orquestrado por um “Orquestrador EDMS” central. O objetivo é garantir escalabilidade, segurança, governança, auditoria, alta disponibilidade e evolução contínua. A arquitetura propõe um modelo event‑driven, com APIs bem definidas, separação clara de responsabilidades e automação de processos de negócio (workflows) com rastreabilidade ponta a ponta.
Princípios de arquitetura
- Separação de responsabilidades por domínio (microserviços independentes, com dados próprios).
- Event-driven + orquestração: cada etapa emite eventos; o Orquestrador EDMS coordena fluxos complexos (sagas) e SLAs.
- Segurança por padrão: criptografia em trânsito e em repouso, políticas de acesso granulares, segregação por tenant.
- Observabilidade total: logging estruturado, métricas, tracing distribuído, auditoria imutável.
- Escalabilidade elástica: serviços stateless com autoscaling; workloads pesados (OCR/ML) em filas/GPU.
- Resiliência: retries, DLQ, idempotência, circuit breakers, bulkheads, e data consistency via padrões (Outbox, CQRS).
- Extensibilidade: esquema de metadados dinâmicos, webhooks, integração com IdP/SSO, conectores externos.
- Conformidade: retenção, legal hold, WORM/immutability, trilha de auditoria, políticas de privacidade (PII), eDiscovery.
Arquitetura de alto nível
- Canal de entrada: API Gateway + Ingestion Service (upload, ingestão em lote, conectores, pré-validações).
- Orquestrador EDMS: coordena workflows e long-running transactions (ex.: Temporal/Camunda/Zeebe).
- Barramento/event bus: pub/sub para eventos de documento (ex.: Kafka/NATS/PubSub), com DLQ.
- Serviços de domínio (microserviços abaixo).
- Armazenamento: objeto (conteúdo), bancos relacionais/NoSQL (metadados e estados), mecanismos de busca (index).
- Observabilidade e segurança transversal: SIEM, KMS/HSM, OPA (policy), secret manager, feature flags, configuração central.
Papéis dos microserviços principais
A seguir, os papéis e melhores práticas para cada microserviço solicitado, além de interações e padrões recomendados.
1) Storage Service (conteúdo binário)
Responsabilidade:
- Receber, armazenar, versionar e servir o conteúdo binário de documentos, anexos e renditions.
- Suporte a objetos grandes: multipart upload, recomeço de upload, checksums (SHA-256), e deduplicação por hash (content-addressable storage).
- Tiers de armazenamento: hot (frequente), warm (intermediário), cold/archival (custo otimizado), com políticas de migração automática.
- Imutabilidade opcional (WORM) para registros/arquivística e compliance.
- Criptografia em repouso (KMS/HSM), controle de chaves por tenant, rotação de chaves.
- Entrega com URLs assinadas (tempo limitado), download acelerado via CDN.
- Suporte a renditions: thumbnails, PDF/A, extrações de página, conversões (ex.: docx->pdf).
Boas práticas:
- Processamento de uploads via pre-signed URLs (o cliente envia direto ao bucket).
- Controle de integridade por ETag/Content-MD5; rejeição de arquivos corrompidos.
- Replicação cross-region para DR; testes regulares de restauração.
2) OCR Service
Responsabilidade:
- Extração de texto e layout (posições, blocos, tabelas) de imagens/PDFs digitalizados.
- Deteção de idioma, deskew/denoise, rotação automática, normalização de qualidade.
- Suporte a diferentes engines e modelos (Tesseract, cloud OCR, layout-aware OCR).
- Geração de saída estruturada: texto, hOCR/ALTO, bounding boxes, confidences.
- Processamento assíncrono em fila; escala horizontal e GPU para lotes grandes.
Boas práticas:
- Evitar OCR se o PDF já for “readable” (texto embedado).
- Produzir métricas de qualidade (ex.: word recall); reprocessar com pipelines mais robustos quando qualidade baixa.
- Emitir eventos “OCRCompleted” com payloads compactos e artefatos pesados no Storage.
3) Data Store (basic data)
Responsabilidade:
- Dados transacionais essenciais: cadastro de tenants, usuários, grupos, unidades organizacionais, tipos de documento básicos, estados de workflow, mapeamento de IDs.
- Operações ACID (RDBMS) e schema estável para integridade referencial.
- Suporte a transações com o Orquestrador (ex.: via Outbox pattern para publicar eventos confiáveis).
Boas práticas:
- Evitar misturar metadados customizáveis aqui (manter na Metadata Service com esquema dinâmico).
- Índices e chaves naturais/UUIDs para garantir unicidade: DocumentId, VersionId, ContentId, TenantId.
4) Metadata Service
Responsabilidade:
- Modelo de metadados flexível: campos padrão e campos custom por tipo de documento/tenant (EAV ou JSON com schema registry).
- Validação por JSON Schema; políticas de obrigatoriedade e máscaras (ex.: validação de CNPJ/CPF).
- Versionamento de metadados; histórico de alterações; rastreamento de quem alterou e quando.
- Integração com o Search & Index Service (indexação full-text e por campo).
- Taxonomias, vocabulários controlados, classificações, tags e labels.
Boas práticas:
- Schema Registry para evolução de campos sem downtime.
- Enriquecimento automático por eventos (ex.: após ML extraction).
- Controles de visibilidade field-level com o Permission Service (ex.: PII só para perfis autorizados).
5) Machine Learning Service (classificação e extração de entidades)
Objetivo:
- Detectar tipo de documento (classificação) e extrair entidades (NLP/NER), inclusive PII, datas, números de contrato, CNPJs etc.
Responsabilidade:
- Endpoint de inferência para classificação e extração.
- Pipeline de treinamento/atualização de modelos; versionamento de modelos; validação e canary deployment.
- Feature store opcional para padronizar dados de treino e inferência.
- Feedback loop: uso de correções humanas em workflows para re-treino (active learning).
- Detecção de drift e monitoramento de qualidade (precision/recall); explicabilidade quando aplicável.
Boas práticas:
- Separar serviço de inferência de serviço de treinamento.
- Gerar “MLClassified”/“EntitiesExtracted” events; manter apenas referências no Storage para artefatos pesados (ex.: embeddings).
- Redação/mascara de PII opcional via Redaction Service (segurança e privacidade).
6) Permission Service
Responsabilidade:
- Autorização granulares: RBAC + ABAC (atributos do usuário, documento, contexto).
- Enforcement centralizado via Policy Engine (ex.: OPA/Rego) e caches locais para baixa latência.
- Suporte a níveis de acesso: coleção, documento, versão, campo (field-level), e ação (ler, baixar, editar, aprovar, compartilhar, redigir).
- Compartilhamento temporário (links com expiração), watermarking dinâmico, restrição por IP/localização.
- Integração com IdP/SSO (OIDC/SAML), MFA, SCIM (provisionamento).
Boas práticas:
- Avaliação de políticas idempotente e auditável; decisões com justificativa para auditoria.
- Suporte a contextos temporais (ex.: acesso válido apenas durante o workflow).
7) Audit and Logging Service
Responsabilidade:
- Trilha de auditoria imutável (WORM-friendly): quem fez o quê, quando, de onde, em qual recurso.
- Logs estruturados, correlação por Trace/Span ID, retention ajustada e envio a SIEM.
- Assinatura/encadeamento dos eventos (hash chain) para prova de não adulteração.
- Exposição de relatórios e exportação para compliance.
Boas práticas:
- Não armazenar payloads sensíveis nos logs; usar redaction.
- Políticas de retenção e rotação de logs; mascarar PII conforme LGPD/GDPR quando aplicável.
8) Workflow and Approval Service
Responsabilidade:
- Motor de workflow (BPMN ou state machine) com tarefas humanas e automações.
- SLAs, timers, escalonamentos, substituições, paralelismo, gateways condicionais, reaprovação.
- Integração com ML/OCR/Metadata: passos automáticos e passos de revisão humana.
- Tarefas: aprovar, rejeitar, pedir correção, redigir PII, solicitar e-sign, publicar.
Boas práticas:
- Orquestração central (sagas) para compor microserviços; compensações em caso de erro.
- External task pattern: workers assíncronos para OCR/ML sem acoplamento forte ao motor.
9) Lifecycle of Document Service (records management)
Responsabilidade:
- Políticas de retenção por tipo de documento/regra de negócio (tempo, evento gatilho).
- Legal hold (suspende expiração e deleção).
- Transição entre estágios: ativo → arquivado → expurgo.
- Geração de evidências de destruição segura; aprovações de disposição quando necessário.
- Modo imutável/record (WORM), inclusive para documentos regulatórios.
Boas práticas:
- Integração com Permission para bloquear ações durante hold.
- Logs completos de ciclo de vida e relatórios de conformidade.
Microserviços e componentes complementares (recomendados)
- API Gateway: roteamento, autenticação, rate limiting, proteção DDoS, quotas, tokens de acesso, mTLS.
- Ingestion Service: uploads, captura em lote, conectores (e-mail, SFTP, scanners, RPA, ERP/CRM), normalização, antivírus, quarantine.
- Virus/Malware Scan Service: análise de segurança em todas as entradas.
- Rendition/Conversion Service: conversões (PDF/A), thumbnails, extração de páginas, split/merge.
- Search & Index Service: full‑text, relevância, filtros por metadados, facetas; highlight; sinônimos; indexação incremental; versão de índice.
- Redaction/Annotation Service: anotação colaborativa, comentários, redactions seletivos (PII), camadas de marcação.
- Notification Service: e-mails, chat, push; templates; eventos de SLA/escalonamento.
- E-signature Service: assinatura eletrônica/qualificada, carimbo do tempo, validação de certificados e cadeia de confiança.
- Export/Reporting Service: relatórios operacionais/compliance, exportações massivas via jobs assíncronos.
- Secrets/Config/Feature Flags: gestão central (ex.: Vault/SM), toggles para rollout seguro.
- Cost & Usage Service (FinOps): custo por tenant, storage por classe, egress/downloads, jobs OCR/ML.
- Tenant Management Service: isolação lógica, limites de cota, chaves de criptografia dedicadas, data residency.
- Data Migration Service: importação de repositórios legados, verificação de integridade e reconciliação.
Fluxos principais (exemplos)
Fluxo A: Upload → OCR → Classificação ML → Indexação → Workflow de Aprovação
- Cliente solicita upload:
- API Gateway → Ingestion Service → Permission check (pode criar?) → Storage pre-signed URL → Upload direto.
- Ingestion publica “DocumentUploaded”.
- OCR (se necessário):
- Orquestrador recebe “DocumentUploaded” e decide acionar OCR.
- OCR pega o conteúdo via URL temporária; gera texto/hOCR; publica “OCRCompleted”.
- Classificação/extração ML:
- Orquestrador chama ML Service com texto e metadados brutos.
- ML retorna tipo de documento e entidades; publica “MLClassified” e “EntitiesExtracted”.
- Metadados e index:
- Metadata Service valida/aplica metadados; publica “MetadataUpdated”.
- Search & Index Service consome eventos e indexa conteúdo e campos.
- Workflow:
- Orquestrador inicia processo BPMN de aprovação de acordo com o tipo de documento.
- Tarefas humanas via UI; Permission Service controla quem pode aprovar/rejeitar.
- Ao aprovar, status final “Published”; ao rejeitar, “NeedsRevision”.
- Auditoria:
- Cada passo emite “AuditEvent” assinado e armazenado em trilha WORM.
Fluxo B: Retenção e Disposição
- Lifecycle Service monitora políticas/eventos gatilho (ex.: data de contrato + N anos).
- Se “Legal Hold” ativo, suspende qualquer ação de expurgo.
- Ao vencer retenção sem hold, cria tarefa de revisão de disposição (opcional).
- Executa expurgo seguro (conteúdo e cópias); gera evidência/fatura de expurgo; audita tudo.
Modelo de dados (identificadores e chaves)
Recomendações de chaves:
- TenantId: isola clientes/organizações.
- DocumentId: UUID global por documento.
- VersionId: identifica cada versão; imutável, com parent para histórico.
- ContentId: hash do conteúdo (dedupe e integridade).
- WorkflowInstanceId: correlação com processo.
- MetadataVersion: versionamento lógico de metadados.
Campos típicos de metadados (exemplos):
- Título, descrição, tipoDocumento, dataDocumento, dataRecebimento, idioma.
- Entidades extraídas: cnpj, cpf, númeroContrato, cliente, fornecedor, valores.
- Classificações e tags.
Controle de concorrência:
- ETag/If-Match para update de metadados.
- Locks leves ou optimistic concurrency.
Eventos (exemplos de payload)
DocumentUploaded:
{
"eventType": "DocumentUploaded",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"contentId": "sha256:...",
"fileName": "contrato.pdf",
"mimeType": "application/pdf",
"sizeBytes": 1234567,
"uploadedBy": "u-abc",
"timestamp": "2025-01-01T12:00:00Z",
"correlationId": "c-uuid"
}
OCRCompleted:
{
"eventType": "OCRCompleted",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"language": "pt",
"qualityScore": 0.93,
"textArtifactUri": "s3://bucket/ocr/d-uuid/v-uuid.txt",
"layoutArtifactUri": "s3://bucket/ocr/d-uuid/v-uuid.alto.xml",
"timestamp": "2025-01-01T12:05:00Z",
"correlationId": "c-uuid"
}
MLClassified:
{
"eventType": "MLClassified",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"modelVersion": "docclass-2.1.0",
"predictedType": "Contrato",
"confidence": 0.97,
"timestamp": "2025-01-01T12:06:30Z",
"correlationId": "c-uuid"
}
EntitiesExtracted:
{
"eventType": "EntitiesExtracted",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"modelVersion": "ner-1.4.3",
"entities": [
{"type": "CNPJ", "value": "12.345.678/0001-90", "confidence": 0.95},
{"type": "NumeroContrato", "value": "CT-2025-00077", "confidence": 0.93},
{"type": "Valor", "value": "R$ 150.000,00", "confidence": 0.9}
],
"timestamp": "2025-01-01T12:07:00Z",
"correlationId": "c-uuid"
}
MetadataUpdated:
{
"eventType": "MetadataUpdated",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"metadataVersion": 5,
"changes": {
"tipoDocumento": {"old": "Indefinido", "new": "Contrato"},
"cnpj": {"old": null, "new": "12.345.678/0001-90"}
},
"updatedBy": "system-ml",
"timestamp": "2025-01-01T12:07:10Z",
"correlationId": "c-uuid"
}
WorkflowApproved:
{
"eventType": "WorkflowApproved",
"tenantId": "t-123",
"documentId": "d-uuid",
"versionId": "v-uuid",
"workflowInstanceId": "w-uuid",
"approvedBy": "u-gestor",
"timestamp": "2025-01-01T12:20:00Z",
"correlationId": "c-uuid"
}
RetentionExpired:
{
"eventType": "RetentionExpired",
"tenantId": "t-123",
"documentId": "d-uuid",
"policyId": "rp-contratos-5anos",
"eligibleSince": "2025-12-31T23:59:59Z",
"legalHold": false,
"timestamp": "2026-01-01T00:00:00Z",
"correlationId": "c-uuid"
}
Segurança e conformidade
- Autenticação: SSO via OIDC/SAML; MFA; rotação de credenciais; políticas de senha e sessão.
- Autorização: Permission Service + OPA; decisões cacheadas e auditáveis; ABAC com contexto (geografia, horário, dispositivo).
- Criptografia: TLS 1.2+ em trânsito; AES-256 em repouso; KMS/HSM; rotação periódica; chaves por tenant; envelope encryption.
- Privacidade/PII: detecção com ML; redaction; minimização; mascaramento de logs; consent management quando aplicável.
- Integridade: checksums; hashing de auditoria encadeado; opcional notarização/ timestamping (ex.: RFC 3161) para evidências.
- Conformidade: suporte a políticas de retenção e legal hold; imutabilidade (WORM); eDiscovery; exportações com cadeia de custódia.
- Anti-malware: escaneamento em ingestão; quarentena; bloqueio de extensões perigosas.
Observabilidade e operação
- Logging estruturado (JSON) com correlationId e userId minimizado (sem PII).
- Métricas: latência por endpoint, taxa de erro, throughput, tempos de OCR/ML, backlog de filas, acurácia ML.
- Tracing distribuído (OpenTelemetry) em todas as chamadas; sampling ajustável.
- Dashboards/SLOs: ex. 99.9% disponibilidade API, TTFB, tempo médio de aprovação, SLA OCR.
- Alertas e on-call: gatilhos por saturação, DLQ growth, drift ML, falhas de replicação de storage.
- Backups/DR: RPO/RTO por serviço; testes de restore; simulações de desastre.
- Gestão de configuração: Config service versionado; feature flags para rollouts graduais.
- Canary/Blue-Green: para serviços críticos (Orquestrador, ML); rollback rápido.
Escalabilidade e resiliência
- Stateless onde possível; usar cache distribuído para dados temporários.
- Fila/stream para workloads pesados (OCR/ML, renditions); auto scaling e workers paralelos.
- Idempotência: chaves de dedupe; safe retries; transacional outbox para eventos consistentes.
- Circuit breakers, timeouts e retries exponenciais; DLQ com reprocessamento manual/automático.
- Sharding por tenant e particionamento por DocumentId para hot partitions de alta concorrência.
- Rate limiting no Gateway para proteção contra abuso.
Multi‑tenancy e isolamento
- Isolamento lógico por TenantId em todos os serviços e dados; opcional isolamento físico por cliente estratégico.
- Chaves de criptografia dedicadas por tenant; políticas e quotas por tenant.
- Relatórios de consumo (FinOps) por tenant: armazenamento, OCR/ML minutos, egress.
Pesquisa e indexação
- Indexação incremental por eventos (MetadataUpdated, OCRCompleted).
- Conteúdo e campos indexados com pipeline de análise (tokenização, sinônimos, stemming).
- Suporte a queries avançadas: filtros por metadados, busca textual com highlight, facetas, ordenação custom.
- Reindexações controladas por versão de esquema; zero downtime reindex.
UI e experiência do usuário
- SPA responsiva; viewer de documentos com zoom, thumbnails, busca interna, comentários e anotações.
- Edição de metadados com validação em tempo real (schemas).
- Tarefas de workflow com caixas de entrada, SLAs, reatribuição, delegação.
- Public links com expiração e marca d’água; download protegido; restrições por política.
Integrações e conectores
- Conectores com e-mail (ingestão por inbox), SFTP, scanners, MFDs, ERPs/CRMs (SAP, Salesforce), ECMs legados.
- Webhooks para eventos relevantes (após aprovação, publicação, expurgo).
- SDKs clientes e documentação OpenAPI; exemplos de uso; testes de contrato (PACT).
Padrões de consistência e dados
- CQRS onde fizer sentido: escrita em serviços de domínio, leitura otimizada via Materialized Views (ex.: para dashboards).
- Transacional outbox para publicar eventos com garantia; consumidores idempotentes.
- Sagas no Orquestrador para coordenar steps e compensações (ex.: falha em conversão ou em aprovação).
Estratégia de migração e governança
- Migração faseada: inventário de repositórios, mapeamento de metadados, testes de amostras.
- Verificação de integridade pós-migração (hash match), reconciliação com fontes.
- Governança de metadados: comitê de taxonomia, controle de versões, catálogo e glossário.
- Treinamento de usuários e material de adoção.
Considerações de custo (FinOps)
- Otimizar OCR/ML por lotes e priorização (ex.: OCR apenas quando necessário).
- Armazenamento por classes (hot/warm/cold) e políticas de transição automática.
- Cache/CDN para downloads frequentes.
- Métricas de custo por tenant e por serviço; orçamentos e alertas.
Exemplos de endpoints (ilustrativos)
Upload (solicita URL de upload):
- POST /v1/documents/upload-urls
- Body: { fileName, mimeType, sizeBytes, tenantId }
- Resposta: { uploadUrl, contentId, documentId, versionId, expiresAt }
Atualizar metadados:
- PATCH /v1/documents/{documentId}/versions/{versionId}/metadata
- Headers: If-Match: {ETag}
- Body: { changes: {…} }
- Enforce: Permission Service + validação de schema.
Busca:
- POST /v1/search/query
- Body: { text, filters: { tipoDocumento, data, tags }, page, size, sort }
Workflows:
- POST /v1/workflows/start
- Body: { documentId, versionId, workflowDefinition, variables }
Riscos e mitigação
- Conteúdo sensível vazando em logs: redaction automático e revisão de campos logados.
- ML drift/perda de qualidade: monitoramento, feedback humano, retreinamento programado.
- DLQs crescendo: alertas, painéis de reprocessamento, melhoria de idempotência.
- Hot partitions: particionamento por hash, balanceamento de carga e cache.
- Dependência de vendor: abstrações, S3-compatible API, camadas de repositório e testes de portabilidade.
Conceitos adicionais importantes (não listados inicialmente)
- API Gateway e Rate Limiting.
- Event Bus e Dead Letter Queues.
- Search & Index Service.
- Ingestion/Connector Service e Anti‑Malware Scan.
- Rendition/Conversion e Redaction/Annotation.
- E-signature/Trust Services.
- Tenant Management, Data Residency e KMS/HSM.
- Secrets/Config/Feature Flags.
- Observabilidade (Logs, Métricas, Tracing) e SIEM.
- FinOps/Cost & Usage.
- Data Migration/Reconciliação.
- Schema Registry e Catalog/Glossário.
- eDiscovery/Legal Hold avançado.
- Notarização/Carimbo do tempo para evidência.
Resumo
- O EDMS proposto segue arquitetura de microserviços, com o Orquestrador EDMS coordenando fluxos complexos (OCR, ML, aprovações, retenção).
- Os serviços centrais cobrem armazenamento, metadados flexíveis, autorização granular, auditoria imutável, workflows robustos e ciclo de vida completo.
- Adoção de eventos, padrões de resiliência, segurança por padrão, observabilidade e práticas de FinOps garantem escalabilidade, confiabilidade e conformidade.
- Serviços adicionais (busca, renditions, e‑signature, anti‑malware, conectores) completam o ecossistema e tornam a solução extensível e preparada para cenários corporativos exigentes.
Se quiser, posso adaptar essa arquitetura ao seu contexto específico: volume mensal de documentos, tipos principais, requisitos de retenção/compliance, integrações necessárias (ERP/CRM), SLAs e restrições orçamentárias. Também posso elaborar um diagrama de componentes e sequências detalhadas do seu caso.