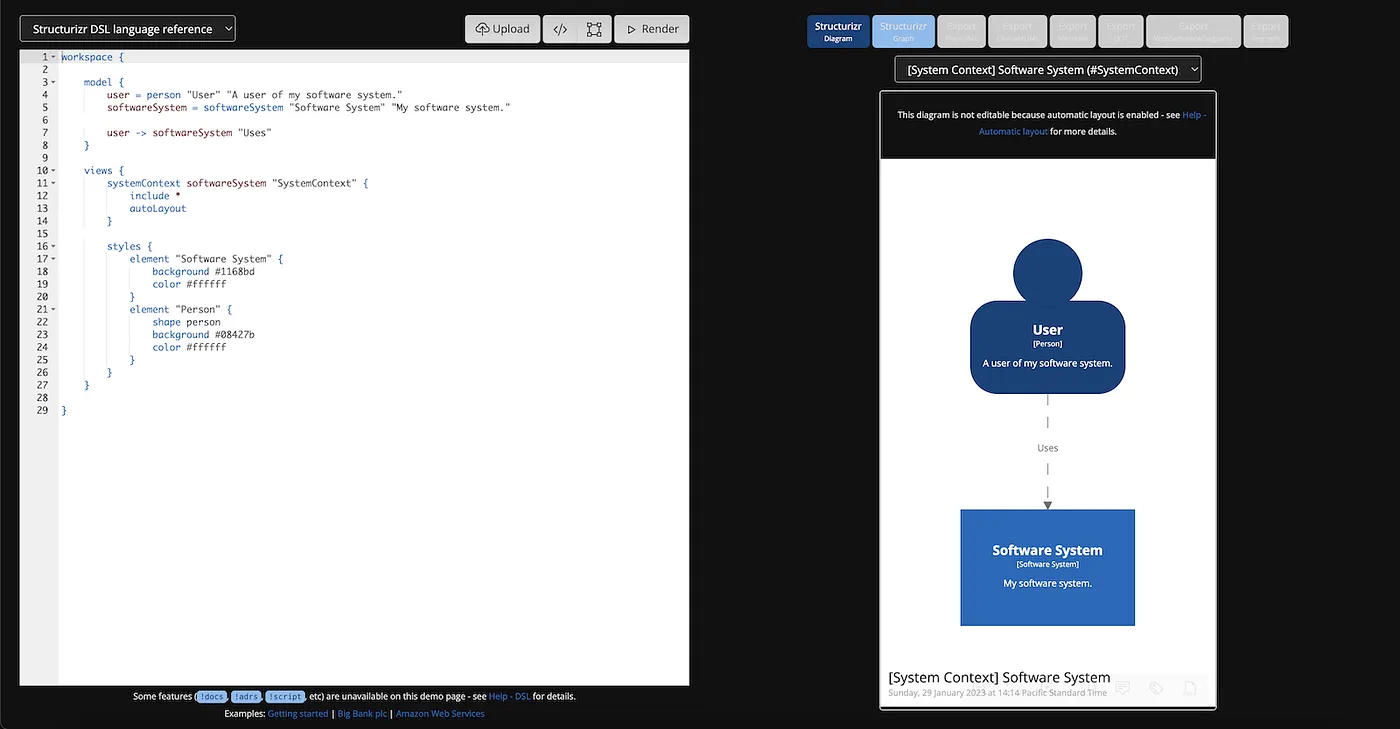
Exemplos de algoritmos e estruturas de dados frequentemente usados em entrevistas técnicas, com explicações e exemplos para ajudar na compreensão:
Two Sum
Dado um array de inteiros, encontre dois números que somam um valor alvo específico.
Abordagem: Use um hash map para armazenar cada número do array e seu índice. Para cada número, verifique se o complemento (target – número) existe no hash map.
Exemplo: nums = [2, 7, 11, 15], target = 9. A solução é [0, 1] (porque nums[0] + nums[1] == 9).
Considerações: Ideal para demonstrar conhecimento de hash tables e otimização de tempo de execução de O(n^2) para O(n).
Reverse a Linked List: Inverta a ordem dos nós em uma linked list.
Abordagem: Use três ponteiros: prev, current e next. Itere pela lista, invertendo a direção dos ponteiros.
Exemplo: 1 -> 2 -> 3 -> 4 -> 5 torna-se 5 -> 4 -> 3 -> 2 -> 1.
Considerações: Importante para entender manipulação de ponteiros e linked lists.
Merge Intervals:
Dado uma coleção de intervalos, combine todos os intervalos sobrepostos.
Abordagem: Ordene os intervalos pelo início e, em seguida, itere sobre eles, combinando os intervalos sobrepostos.
Exemplo: [[1,3],[2,6],[8,10],[15,18]] torna-se [[1,6],[8,10],[15,18]].
Considerações: Demonstra conhecimento de algoritmos de ordenação e manipulação de intervalos.
Longest Substring Without Repeating Characters:
Encontre o comprimento da maior substring sem caracteres repetidos.
Abordagem: Use a técnica de sliding window com um hash set para rastrear os caracteres no intervalo atual.
Exemplo: Para “abcabcbb”, a resposta é 3 (“abc”).
Considerações: Útil para demonstrar otimização de algoritmos com sliding window.
Binary Tree Inorder Traversal:
Percorra uma binary tree usando a ordem inorder (esquerda, raiz, direita).
Abordagem: Use recursão ou uma pilha para implementar a travessia inorder.
Exemplo: Para uma árvore com raiz 1, esquerda 2, direita 3, a travessia inorder é 2 -> 1 -> 3.
Considerações: Fundamental para entender algoritmos de travessia de árvores.
Valid Parentheses:
Determine se uma string contendo parênteses é válida (ou seja, cada parêntese de abertura tem um parêntese de fechamento correspondente).
Abordagem: Use uma pilha para rastrear os parênteses de abertura. Quando encontrar um parêntese de fechamento, verifique se corresponde ao parêntese de abertura no topo da pilha.
Exemplo: “()[]{}” é válido, “(]” não é.
Considerações: Demonstra conhecimento de estruturas de pilha e correspondência de caracteres.
Search in Rotated Sorted Array:
Pesquise um valor em um array ordenado que foi rotacionado.
Abordagem: Use uma variação da busca binária. Encontre o ponto de rotação e, em seguida, execute a busca binária na metade apropriada do array.
Exemplo: [4,5,6,7,0,1,2], target = 0. A resposta é 4 (índice de 0).
Considerações: Demonstra conhecimento de busca binária e manipulação de arrays rotacionados.
Merge Two Sorted Lists:
Combine duas sorted linked lists em uma única sorted linked list.
Abordagem: Use um ponteiro para rastrear a cabeça da nova lista e compare os nós das duas listas para determinar qual nó adicionar à nova lista.
Exemplo: 1->2->4, 1->3->4 torna-se 1->1->2->3->4->4.
Considerações: Importante para entender manipulação de linked lists e algoritmos de ordenação.
Maximum Subarray:
Encontre a soma máxima de um subarray contíguo.
Abordagem: Use o algoritmo de Kadane, que mantém a soma máxima atual e a soma máxima até o momento.
Exemplo: [-2,1,-3,4,-1,2,1,-5,4]. A resposta é 6 ([4,-1,2,1]).
Considerações: Demonstra conhecimento de programação dinâmica e otimização de algoritmos.
Word Break:
Determine se uma string pode ser segmentada em uma sequência de palavras do dicionário.
Abordagem: Use programação dinâmica para construir uma tabela booleana indicando se cada prefixo da string pode ser segmentado.
Exemplo: s = “leetcode”, wordDict = [“leet”, “code”]. A resposta é true.
Considerações: Demonstra conhecimento de programação dinâmica e manipulação de strings.
Coin Change:
Dado um conjunto de denominações de moedas e um valor alvo, encontre o número mínimo de moedas necessárias para atingir o valor alvo.
Abordagem: Use programação dinâmica para construir uma tabela que armazena o número mínimo de moedas necessárias para cada valor de 0 ao valor alvo.
Exemplo: coins = [1, 2, 5], amount = 11. A resposta é 3 (5 + 5 + 1).
Considerações: Demonstra conhecimento de programação dinâmica e problemas de otimização.
Climbing Stairs:
Calcule o número de maneiras distintas de subir até o topo de uma escada com n degraus, onde você pode subir 1 ou 2 degraus de cada vez.
Abordagem: Use programação dinâmica. O número de maneiras de subir até o degrau n é a soma do número de maneiras de subir até o degrau n-1 e o degrau n-2.
Exemplo: Para n = 3, a resposta é 3 (1+1+1, 1+2, 2+1).
Considerações: Demonstra conhecimento de programação dinâmica e sequências de Fibonacci.
Subtree of Another Tree:
Determine se uma árvore é uma subárvore de outra árvore.
Abordagem: Percorra a árvore maior e, para cada nó, verifique se a subárvore enraizada nesse nó é idêntica à árvore menor.
Considerações: Importante para entender algoritmos de travessia de árvores e recursão.
Product of Array Except Self:
Dado um array de inteiros, retorne um novo array onde cada elemento no índice i é o produto de todos os elementos no array original, exceto o elemento no índice i.
Abordagem: Calcule os produtos prefixados e sufixados do array e, em seguida, multiplique-os para obter o resultado.
Exemplo: [1,2,3,4] torna-se [24,12,8,6].
Considerações: Demonstra conhecimento de manipulação de arrays e otimização de algoritmos.
Valid Anagram:
Determine se duas strings são anagramas uma da outra (ou seja, contêm os mesmos caracteres na mesma quantidade, mas em uma ordem diferente).
Abordagem: Use um hash map para contar a frequência de cada caractere em ambas as strings. Se os hash maps forem iguais, as strings são anagramas.
Exemplo: “anagram” e “nagaram” são anagramas.
Considerações: Demonstra conhecimento de hash maps e manipulação de strings.
Linked List Cycle:
Determine se uma linked list contém um ciclo.
Abordagem: Use o algoritmo da lebre e da tartaruga (dois ponteiros, um movendo-se duas vezes mais rápido que o outro). Se houver um ciclo, os ponteiros se encontrarão.
Considerações: Importante para entender manipulação de linked lists e algoritmos de detecção de ciclos.
Find Minimum in Rotated Sorted Array:
Encontre o elemento mínimo em um array ordenado que foi rotacionado.
Abordagem: Use uma variação da busca binária. Compare o elemento do meio com o elemento mais à direita para determinar qual metade do array contém o mínimo.
Considerações: Demonstra conhecimento de busca binária e manipulação de arrays rotacionados.
Combination Sum:
Dado um conjunto de números candidatos e um valor alvo, encontre todas as combinações únicas dos números candidatos que somam o valor alvo.
Abordagem: Use backtracking para explorar todas as combinações possíveis dos números candidatos.
Considerações: Demonstra conhecimento de backtracking e algoritmos de busca.
House Robber:
Dado um array de inteiros representando os valores das casas ao longo de uma rua, determine o valor máximo que você pode roubar sem roubar duas casas adjacentes.
Abordagem: Use programação dinâmica para construir uma tabela que armazena o valor máximo que você pode roubar até cada casa.
Considerações: Demonstra conhecimento de programação dinâmica e problemas de otimização.
Longest Palindromic Substring:
Encontre a substring palindrômica mais longa em uma determinada string.
Abordagem: Use programação dinâmica ou expanda ao redor do centro para encontrar a substring palindrômica mais longa.
Considerações: Demonstra conhecimento de programação dinâmica e manipulação de strings.
Word Ladder:
Dado uma palavra inicial, uma palavra final e um dicionário de palavras, encontre o comprimento da sequência de transformação mais curta da palavra inicial para a palavra final, usando apenas palavras do dicionário e alterando apenas uma letra de cada vez.
Abordagem: Use a busca em largura (BFS) para explorar o espaço de busca de palavras possíveis.
Considerações: Demonstra conhecimento de algoritmos de busca em grafos e manipulação de strings.
Pow(x, n): Implemente a função para calcular x elevado à potência n.
Abordagem: Use recursão e divida e conquiste para calcular a potência de forma eficiente.
Considerações: Demonstra conhecimento de recursão e algoritmos de divisão e conquista.
Rotate Image:
Gire uma matriz quadrada (imagem) 90 graus no sentido horário.
Abordagem: Inverta a matriz ao longo da diagonal principal e, em seguida, inverta cada linha.
Considerações: Demonstra conhecimento de manipulação de matrizes e operações in-place.
Group Anagrams:
Dado um array de strings, agrupe os anagramas juntos.
Abordagem: Use um hash map para mapear cada string para sua versão ordenada. Todas as strings que são anagramas umas das outras terão a mesma versão ordenada.
Considerações: Demonstra conhecimento de hash maps e manipulação de strings.
Maximum Depth of Binary Tree:
Encontre a profundidade máxima de uma binary tree.
Abordagem: Use recursão para percorrer a árvore e calcular a profundidade de cada nó. A profundidade máxima é a profundidade máxima de qualquer nó na árvore.
Considerações: Fundamental para entender algoritmos de travessia de árvores e recursão.
Insert Interval:
Dado uma lista de intervalos não sobrepostos, insira um novo intervalo na lista.
Abordagem: Encontre a posição correta para inserir o novo intervalo e, em seguida, combine quaisquer intervalos sobrepostos.
Considerações: Demonstra conhecimento de manipulação de intervalos e algoritmos de ordenação.
Subsets:
Dado um conjunto de números distintos, retorne todos os subconjuntos possíveis.
Abordagem: Use backtracking para gerar todos os subconjuntos possíveis.
Considerações: Demonstra conhecimento de backtracking e algoritmos de busca.
Palindromic Substrings:
Dado uma string, conte o número de substrings palindrômicas.
Abordagem: Use programação dinâmica ou expanda ao redor do centro para encontrar todas as substrings palindrômicas.
Considerações: Demonstra conhecimento de programação dinâmica e manipulação de strings.
Minimum Path Sum:
Dado uma grade de números não negativos, encontre um caminho da parte superior esquerda para a parte inferior direita que minimize a soma de todos os números ao longo do caminho.
Abordagem: Use programação dinâmica para construir uma tabela que armazena a soma mínima do caminho até cada célula na grade.
Considerações: Demonstra conhecimento de programação dinâmica e problemas de otimização.
3Sum:
Dado um array de inteiros, encontre todos os triplos únicos que somam zero.
Abordagem: Ordene o array e, em seguida, itere sobre ele. Para cada elemento, use dois ponteiros para encontrar os dois outros elementos que somam zero.
Considerações: Demonstra conhecimento de algoritmos de ordenação e manipulação de arrays.
Find Peak Element:
Encontre um elemento de pico em um array. Um elemento de pico é um elemento que é maior que seus vizinhos.
Abordagem: Use busca binária para encontrar um elemento de pico.
Considerações: Demonstra conhecimento de busca binária e manipulação de arrays.
Serialize and Deserialize Binary Tree:
Serialize uma binary tree em uma string e, em seguida, desserialize a string de volta em uma binary tree.
Abordagem: Use uma travessia pré-ordem ou pós-ordem para serializar a árvore. Use a mesma travessia para desserializar a árvore.
Considerações: Importante para entender algoritmos de travessia de árvores e serialização/desserialização de dados.
Partition Equal Subset Sum:
Dado um array de inteiros, determine se o array pode ser particionado em dois subconjuntos com somas iguais.
Abordagem: Use programação dinâmica para construir uma tabela que armazena se cada soma possível pode ser alcançada usando um subconjunto dos números no array.
Considerações: Demonstra conhecimento de programação dinâmica e problemas de otimização.
Sort Colors:
Dado um array de cores (representadas por 0, 1 e 2), ordene as cores in-place.
Abordagem: Use o algoritmo de partição de três vias para ordenar as cores.
Considerações: Demonstra conhecimento de algoritmos de ordenação e operações in-place.
Letter Combinations of a Phone Number:
Dado um número de telefone, retorne todas as combinações de letras possíveis que o número pode representar.
Abordagem: Use backtracking para gerar todas as combinações possíveis de letras.
Considerações: Demonstra conhecimento de backtracking e algoritmos de busca.
Best Time to Buy and Sell Stock:
Dado um array de preços de ações, encontre o lucro máximo que você pode obter comprando e vendendo uma ação uma vez.
Abordagem: Mantenha o controle do preço mínimo e do lucro máximo. Itere sobre o array e atualize o preço mínimo e o lucro máximo conforme necessário.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
Top K Frequent Elements:
Dado um array de inteiros, retorne os k elementos mais frequentes.
Abordagem: Use um hash map para contar a frequência de cada elemento. Em seguida, use uma fila de prioridade para armazenar os k elementos mais frequentes.
Considerações: Demonstra conhecimento de hash maps, filas de prioridade e algoritmos de ordenação.
Kth Largest Element in an Array:
Encontre o k-ésimo maior elemento em um array.
Abordagem: Use o algoritmo quickselect para encontrar o k-ésimo maior elemento.
Considerações: Demonstra conhecimento de algoritmos de seleção e manipulação de arrays.
Unique Paths:
Dado uma grade de m x n, encontre o número de caminhos únicos da parte superior esquerda para a parte inferior direita.
Abordagem: Use programação dinâmica para construir uma tabela que armazena o número de caminhos únicos até cada célula na grade.
Considerações: Demonstra conhecimento de programação dinâmica e problemas de otimização.
Longest Common Subsequence:
Encontre a subsequência comum mais longa de duas strings.
Abordagem: Use programação dinâmica para construir uma tabela que armazena o comprimento da subsequência comum mais longa de cada par de prefixos das duas strings.
Considerações: Demonstra conhecimento de programação dinâmica e manipulação de strings.
Implement Trie (Prefix Tree):
Implemente uma estrutura de dados trie (árvore de prefixos).
Abordagem: Use um nó para representar cada caractere em um prefixo. Cada nó tem um ponteiro para seus filhos e um sinalizador que indica se o nó representa o final de uma palavra.
Considerações: Importante para entender estruturas de dados de árvores e manipulação de strings.
Binary Search:
Implemente o algoritmo de busca binária.
Abordagem: Compare o valor alvo com o elemento do meio do array. Se o valor alvo for menor que o elemento do meio, pesquise na metade esquerda do array. Se o valor alvo for maior que o elemento do meio, pesquise na metade direita do array.
Considerações: Fundamental para entender algoritmos de busca e manipulação de arrays.
Flood Fill:
Dado uma imagem e uma coordenada inicial, preencha a região conectada da imagem com uma nova cor.
Abordagem: Use a busca em profundidade (DFS) ou a busca em largura (BFS) para percorrer a região conectada e preenchê-la com a nova cor.
Considerações: Demonstra conhecimento de algoritmos de busca em grafos e manipulação de matrizes.
Course Schedule:
Dado uma lista de cursos e seus pré-requisitos, determine se é possível concluir todos os cursos.
Abordagem: Use a detecção de ciclos em grafos. Construa um grafo onde cada nó representa um curso e cada aresta representa um pré-requisito. Se o grafo contiver um ciclo, não é possível concluir todos os cursos.
Considerações: Demonstra conhecimento de algoritmos de grafos e detecção de ciclos.
Lowest Common Ancestor of a Binary Search Tree:
Encontre o ancestral comum mais baixo de dois nós em uma binary search tree.
Abordagem: Percorra a árvore. Se ambos os nós estiverem na subárvore esquerda, o ancestral comum mais baixo está na subárvore esquerda. Se ambos os nós estiverem na subárvore direita, o ancestral comum mais baixo está na subárvore direita. Caso contrário, o nó atual é o ancestral comum mais baixo.
Considerações: Importante para entender algoritmos de travessia de árvores e propriedades de binary search trees.
Basic Calculator II:
Implemente uma calculadora básica para avaliar expressões de string.
Abordagem: Use uma pilha para armazenar os operandos e operadores. Itere sobre a string e execute as operações na ordem correta.
Considerações: Demonstra conhecimento de estruturas de pilha e manipulação de strings.
Jump Game:
Dado um array de inteiros, onde cada elemento representa o número máximo de degraus que você pode dar para frente, determine se você pode chegar ao último índice.
Abordagem: Mantenha o controle do índice mais distante que você pode alcançar. Itere sobre o array e atualize o índice mais distante conforme necessário. Se você puder alcançar o último índice, retorne true. Caso contrário, retorne false.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
Zigzag Conversion:
Converta uma string em um padrão em zigue-zague com um determinado número de linhas.
Abordagem: Itere sobre a string e adicione cada caractere à linha apropriada. Em seguida, concatene as linhas para obter a string convertida.
Considerações: Demonstra conhecimento de manipulação de strings e padrões.
Set Matrix Zeroes:
Dado uma matriz, se um elemento for 0, defina toda a sua linha e coluna como 0.
Abordagem: Use o primeiro elemento de cada linha e coluna para rastrear se a linha ou coluna deve ser definida como 0.
Considerações: Demonstra conhecimento de manipulação de matrizes e operações in-place.
Permutations:
Dado um array de números distintos, retorne todas as permutações possíveis.
Abordagem: Use backtracking para gerar todas as permutações possíveis.
Considerações: Demonstra conhecimento de backtracking e algoritmos de busca.
LRU Cache:
Designe uma cache LRU (Least Recently Used).
Abordagem: Use uma combinação de um hash map e uma doubly linked list. O hash map armazena os pares chave-valor e a doubly linked list rastreia a ordem em que as chaves foram acessadas.
Considerações: Demonstra conhecimento de hash maps, linked lists e design de estruturas de dados.
N-Queens:
Resolva o problema das N-Rainhas. Coloque N rainhas em um tabuleiro de xadrez de N x N para que nenhuma rainha ataque outra.
Abordagem: Use backtracking para explorar todas as possíveis colocações das rainhas.
Considerações: Demonstra conhecimento de backtracking e algoritmos de busca.
Find Median from Data Stream:
Designe uma estrutura de dados que possa encontrar a mediana de um fluxo de dados.
Abordagem: Use duas filas de prioridade: uma fila máxima para armazenar a metade inferior dos dados e uma fila mínima para armazenar a metade superior dos dados.
Considerações: Demonstra conhecimento de filas de prioridade e design de estruturas de dados.
Maximum Product Subarray:
Encontre o produto máximo de um subarray contíguo.
Abordagem: Mantenha o controle do produto máximo atual, do produto mínimo atual e do produto máximo até o momento. Itere sobre o array e atualize os produtos conforme necessário.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
Binary Tree Maximum Path Sum:
Encontre a soma máxima do caminho em uma binary tree.
Abordagem: Use recursão para percorrer a árvore e calcular a soma máxima do caminho para cada nó. A soma máxima do caminho é a soma máxima do caminho de qualquer nó na árvore.
Considerações: Importante para entender algoritmos de travessia de árvores e recursão.
Search a 2D Matrix:
Pesquise um valor em uma matriz 2D ordenada.
Abordagem: Use busca binária para encontrar a linha que pode conter o valor alvo. Em seguida, use busca binária novamente para encontrar o valor alvo na linha.
Considerações: Demonstra conhecimento de busca binária e manipulação de matrizes.
Valid Sudoku:
Determine se um tabuleiro de Sudoku é válido.
Abordagem: Verifique se cada linha, coluna e bloco 3×3 contém os dígitos de 1 a 9 sem repetição.
Considerações: Demonstra conhecimento de manipulação de matrizes e restrições.
Container with Most Water:
Dado um array de inteiros que representam as alturas das linhas verticais, encontre o contêiner que pode conter mais água.
Abordagem: Use dois ponteiros, um no início do array e outro no final do array. Mova o ponteiro com a menor altura em direção ao centro do array. Calcule a área do contêiner em cada etapa e atualize a área máxima conforme necessário.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
Design Add and Search Words Data Structure:
Designe uma estrutura de dados que suporte adicionar novas palavras e pesquisar palavras que correspondam a um padrão.
Abordagem: Use uma trie (árvore de prefixos) para armazenar as palavras. Use a busca em profundidade (DFS) para pesquisar palavras que correspondam a um padrão.
Considerações: Demonstra conhecimento de estruturas de dados de árvores e algoritmos de busca.
Task Scheduler:
Dado um array de tarefas e um número inteiro n, encontre o número mínimo de unidades de tempo necessárias para concluir todas as tarefas.
Abordagem: Calcule a frequência de cada tarefa. O número mínimo de unidades de tempo é o número de vezes que a tarefa mais frequente precisa ser executada, mais o número de vezes que as outras tarefas precisam ser executadas.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
Find the Duplicate Number:
Dado um array de inteiros contendo n + 1 inteiros onde cada inteiro está entre 1 e n (inclusive), prove que pelo menos um número duplicado deve existir. Suponha que haja apenas um número duplicado, encontre o número duplicado.
Abordagem: Use o algoritmo da lebre e da tartaruga (detecção de ciclo de Floyd).
Considerações: Demonstra conhecimento de algoritmos de detecção de ciclos e manipulação de arrays.
Maximum Width of Binary Tree:
Dado uma binary tree, escreva uma função para obter a largura máxima da árvore. A largura de uma linha é definida como o número de nós entre os dois nós não nulos mais distantes, que podem ser após o valor nulo.
Abordagem: Use a busca em largura (BFS) e atribua um índice a cada nó com base em sua posição.
Considerações: Demonstra conhecimento de algoritmos de travessia de árvores e manipulação de dados.
Evaluate Reverse Polish Notation:
Avalie o valor de uma expressão de Notação Polonesa Reversa (RPN), também conhecida como notação pós-fixada.
Abordagem: Use uma pilha para armazenar os operandos. Quando encontrar um operador, retire os dois operandos do topo da pilha, execute a operação e coloque o resultado de volta na pilha.
Considerações: Demonstra conhecimento de estruturas de pilha e manipulação de strings.
Spiral Matrix:
Dado uma matriz m x n, retorne todos os elementos da matriz em ordem espiral.
Abordagem: Mantenha o controle dos limites da matriz. Itere sobre a matriz em ordem espiral e atualize os limites conforme necessário.
Considerações: Demonstra conhecimento de manipulação de matrizes e padrões.
Surrounded Regions:
Dado uma matriz m x n de caracteres, capture todas as regiões ‘O’ que estão cercadas por ‘X’.
Abordagem: Percorra a borda da matriz. Para cada ‘O’ na borda, use a busca em profundidade (DFS) para marcar todas as regiões conectadas ‘O’ como ‘T’. Em seguida, itere sobre a matriz novamente. Converta todos os ‘O’ restantes em ‘X’ e todos os ‘T’ em ‘O’.
Considerações: Demonstra conhecimento de algoritmos de busca em grafos e manipulação de matrizes.
Valid Palindrome:
Dado uma string, determine se é um palíndromo, considerando apenas caracteres alfanuméricos e ignorando maiúsculas e minúsculas.
Abordagem: Use dois ponteiros, um no início da string e outro no final da string. Mova os ponteiros em direção ao centro da string, ignorando caracteres não alfanuméricos. Compare os caracteres em cada etapa. Se os caracteres forem diferentes, a string não é um palíndromo.
Considerações: Demonstra conhecimento de manipulação de strings e padrões.
Jump Game II:
Dado um array de inteiros, onde cada elemento representa o número máximo de degraus que você pode dar para frente, encontre o número mínimo de degraus necessários para chegar ao último índice.
Abordagem: Use uma abordagem gananciosa. Mantenha o controle do índice mais distante que você pode alcançar e o número de degraus que você deu. Itere sobre o array e atualize o índice mais distante e o número de degraus conforme necessário.
Considerações: Demonstra conhecimento de problemas de otimização e manipulação de arrays.
LRU Cache:
(Repetição do item 51, mantido para manter a sequência original) Designe uma cache LRU (Least Recently Used).
Abordagem: Use uma combinação de um hash map e uma doubly linked list. O hash map armazena os pares chave-valor e a doubly linked list rastreia a ordem em que as chaves foram acessadas.
Considerações: Demonstra conhecimento de hash maps, linked lists e design de estruturas de dados.
Longest Consecutive Sequence:
Dado um array de inteiros, encontre o comprimento da sequência consecutiva mais longa.
Abordagem: Use um hash set para armazenar todos os números no array. Itere sobre o array e, para cada número, verifique se é o início de uma sequência consecutiva. Se for, encontre o comprimento da sequência.
Considerações: Demonstra conhecimento de hash sets e manipulação de arrays.
Remove Nth Node From End of List:
Dado uma linked list, remova o n-ésimo nó do final da lista e retorne a cabeça da lista.
Abordagem: Use dois ponteiros. Mova o primeiro ponteiro n nós para frente. Em seguida, mova ambos os ponteiros até que o primeiro ponteiro chegue ao final da lista. Remova o nó apontado pelo segundo ponteiro.
Considerações: Importante para entender manipulação de linked lists.
Integer to Roman:
Converta um inteiro em um numeral romano.
Abordagem: Use um hash map para armazenar os valores dos numerais romanos. Itere sobre os numerais romanos em ordem decrescente e subtraia o valor do numeral romano do inteiro até que o inteiro seja 0.
Considerações: Demonstra conhecimento de hash maps e manipulação de números.
Roman to Integer:
Converta um numeral romano em um inteiro.
Abordagem: Use um hash map para armazenar os valores dos numerais romanos. Itere sobre o numeral romano e adicione o valor de cada numeral romano ao inteiro. Se o valor do numeral romano atual for menor que o valor do próximo numeral romano, subtraia o valor do numeral romano atual do inteiro.
Considerações: Demonstra conhecimento de hash maps e manipulação de números.
String to Integer (atoi):
Abordagem: Ignore espaços em branco, leia o sinal (se houver) e converta os caracteres numéricos subsequentes em um número inteiro.
Considerações: Lide com sobrecarga e valores fora do intervalo.
Zigzag Conversion:
Abordagem: Crie linhas que armazenem caracteres enquanto percorrem a string em zigue-zague, depois concatene os resultados.
Considerações: Evidencia manipulação de índices e padrões.
Multiply Strings:
Abordagem: Simule multiplicação manual, acumulando resultados parciais antes de somar.
Considerações: Desafio em otimizar manipulação de strings.
Median of Two Sorted Arrays:
Abordagem: Use busca binária para encontrar a mediana de forma eficiente.
Considerações: Demonstra habilidade em busca binária em contextos complexos.
Longest Increasing Subsequence:
Abordagem: Use programação dinâmica ou algoritmo de paciência para encontrar a sequência.
Considerações: Identificação de subsequências e otimização.
Reverse Nodes in k-Group:
Abordagem: Inverta nós de k em k numa lista ligada.
Considerações: Conhecimento aprofundado de manipulação de linked lists.
Word Search:
Abordagem: Use backtracking para verificar a presença de uma palavra em uma grade de caracteres.
Considerações: Algoritmos de busca em matrizes.
Edit Distance:
Abordagem: Use programação dinâmica para calcular a menor edição para transformar uma string em outra.
Considerações: Problemas de transformação e distâncias mínimas.
Minimum Window Substring:
Abordagem: Use a técnica de sliding window para encontrar o menor substrato que contém todos os caracteres.
Considerações: Manipulação de substrings e otimização.
Kth Largest Element in an Array:
Abordagem: Use heap ou Quickselect para eficiência.
Considerações: Algoritmos de ordenação e seleção.
Trapping Rain Water:
Abordagem: Use dois ponteiros para calcular a água retida entre colunas.
Considerações: Análise de problemas de espaço e volume.
Binary Search Tree Iterator:
Abordagem: Use uma pilha para implementar a travessia em ordem.
Considerações: Orthogonalidade em travessias de árvores.
Clone Graph:
Abordagem: Use busca em profundidade ou largura para clonar o gráfico.
Considerações: Estruturas de dados e clonagem.
Longest Common Subsequence:
Abordagem: Use programação dinâmica para encontrar a subsequência comum mais longa entre duas strings.
Considerações: Sequências e problemas de alinhamento.
Graph Valid Tree:
Abordagem: Verifique conectividade e aciclicidade usando BFS ou DFS.
Considerações: Estrutura de grafos e validez de árvores.
Game of Life:
Abordagem: Simule as transições de células vivas e mortas em uma matriz.
Considerações: Manipulação de matrizes e simulação.
Number of Islands:
Abordagem: Use BFS ou DFS para contar e marcar as ilhas em uma matriz.
Considerações: Conectividade em 2D.
Lowest Common Ancestor of a Binary Tree:
Abordagem: Use recursão para localizar o ancestral comum.
Considerações: Travessia de árvores e aninhamento.
Decode Ways:
Abordagem: Use programação dinâmica para calcular maneiras de decodificar uma string numérica em letras.
Considerações: Problemas de mapeamento e interpretação.
House Robber II:
Abordagem: Use programação dinâmica, considerando casas organizadas em um círculo.
Considerações: Otimização de problemas cíclicos.
Randomized Set:
Abordagem: Use uma combinação de array e hash map para permitir operações de tempo constante.
Considerações: Estruturas de dados de conjunto.
Sliding Window Maximum:
Abordagem: Use um deque para obter máximos em um intervalo deslizante.
Considerações: Algoritmos de janelas deslizantes.
Merge K Sorted Lists:
Abordagem: Use uma fila de prioridade para mesclar as listas eficientemente.
Considerações: Estruturas de dados de filas de prioridade.
Binary Tree Right Side View:
Abordagem: Use BFS para capturar a visão direita de uma árvore.
Considerações: Visualização e travessia de árvores.
Palindrome Partitioning:
Abordagem: Use backtracking para encontrar todas as partições palindrômicas possíveis.
Considerações: Particionamento e reconhecimento de padrões.
Vertical Order Traversal of a Binary Tree:
Abordagem: Use BFS com coordenadas para imprimir a ordem vertical.
Considerações: Visualização em árvores e coordenadas.
Peeking Iterator:
Abordagem: Adapte um iterador para permitir espiar o próximo elemento.
Considerações: Manipulação de iteradores.
Kth Smallest Element in a BST: –
Abordagem: Use in-order traversal para encontrar o k-ésimo elemento. – Considerações: Ordem de árvores binárias e travessia.