| Question | Useful Answer |
|---|---|
| 1. How do you handle stress and pressure? | I prioritize tasks and break them down into manageable steps. I also practice mindfulness techniques to stay calm and focused. |
| 2. Can you give an example of a conflict you resolved? | In my last job, I facilitated a discussion between two team members who disagreed on project direction. By listening to both sides, we found a compromise that satisfied everyone. |
| 3. Describe a time you worked in a team. | I collaborated with a diverse team on a presentation. We divided tasks based on each member’s strengths, ensuring a well-rounded final product. |
| 4. How do you adapt to changes in the workplace? | I embrace change by staying open-minded and flexible. I assess the situation and adjust my approach as needed, which helps me stay productive. |
| 5. Tell me about a time you received constructive criticism. | I once received feedback on my presentation skills. I took it positively and enrolled in a workshop to improve, which ultimately enhanced my confidence. |
| 6. How do you prioritize your work? | I use a to-do list and the Eisenhower Matrix to distinguish between urgent and important tasks, ensuring I focus on what truly matters. |
| 7. Describe a time when you had to learn something quickly. | When our software was updated unexpectedly, I dedicated time after work to learn the new features, which allowed me to assist my team and minimize downtime. |
| 8. How do you handle failure? | I view failure as a learning opportunity. After a setback, I analyze what went wrong, adjust my approach, and use the experience to grow. |
| 9. Can you describe your communication style? | I strive to be clear and concise, actively listening to others and ensuring that my message is understood. I encourage feedback to promote open dialogue. |
| 10. How do you motivate yourself and others? | I set personal goals and celebrate small victories. I also encourage my colleagues by acknowledging their contributions and reminding them of our shared goals. |
| 11. What do you do when you disagree with a decision made at work? | I express my concerns respectfully and provide alternative solutions. If the decision stands, I support the team and focus on executing it effectively. |
| 12. How do you build relationships at work? | I make an effort to connect with my colleagues by engaging in conversations, showing genuine interest in their work, and collaborating on projects. |
| 13. Describe a time when you had to give difficult feedback. | I once had to inform a team member about their performance issues. I approached the conversation with empathy, focusing on specific behaviors and offering support for improvement. |
| 14. How do you approach problem-solving? | I analyze the situation, gather information, brainstorm possible solutions, and evaluate the best course of action. I also involve others for diverse perspectives. |
| 15. Can you give an example of how you’ve shown leadership? | I led a project team to meet a tight deadline by organizing regular check-ins and delegating tasks according to each member’s strengths, which resulted in successful completion. |
| 16. How do you ensure effective collaboration in a team? | I promote open communication and establish clear goals and roles. I encourage team members to share ideas and feedback, fostering a collaborative environment. |
| 17. What strategies do you use to manage your time effectively? | I utilize scheduling tools and set specific time blocks for tasks. I also review my progress daily to adjust my plans as needed. |
| 18. How do you handle tight deadlines? | I remain focused and organized, prioritizing key tasks. If necessary, I communicate with my team to ensure we’re aligned and can collaborate efficiently under pressure. |
| 19. Describe a situation where you had to be adaptable. | During a major project shift, I quickly reassessed our goals and led the team in adjusting our strategies, which helped us stay on track despite the changes. |
| 20. How do you approach networking? | I view networking as building genuine relationships. I engage with others by attending events, reaching out for informational interviews, and staying in touch to cultivate connections. |
Author Archives: Luis Fernando Chaim
Remote Job – 30 websites
Here are 30 websites to find remote jobs that pay in USD:
1. Remote Woman.
-Women have the opportunity to work from home, enhancing their productivity and flexibility
🔗 Link: remotewoman.com
2. Wellfound
– Unique jobs
– Top Companies
– Over 130,000 jobs
🔗 Link: https://wellfound.com/jobs
3. RemoteOK
– Over 600,000 jobs
– Work from anywhere
– The no. 1 remote job board
🔗 Link: https://remoteok.com
4. Remotive
– Over 30,000 jobs
– Vetted tech companies
– Full remote job opportunities
🔗 Link: https://remotive.com
5. Remote.co
– Hand curated
– Grow remotely
– 146 remote companies
🔗 Link: https://lnkd.in/eYgwD4bB
6. FlexJobs – Vetted Remote & Flexible Jobs
– 50+ categories
– Over 42,000 jobs
– 5,509 companies
🔗Link: https://www.flexjobs.com
7. JustRemote
– Jobs that fit your life
– Fully and partially remote
– Top remote working companies
🔗Link: https://lnkd.in/d5ZqAXm
8. PowerToFly
-2987 Remote jobs
– Jobs tailored to your skillset
– Land a job at a company committed to diversity & inclusion
🔗Link: https://powertofly.com/
9. Al Jobs
– Top Al job board
– Full-time remote jobs
– Top 1% of Al companies
🔗Link: https://theaijobboard.com
10. Toptal
– Top Companies
– Exclusive network
– Community of experts
🔗Link: https://www.toptal.com
11. Working Nomads Nomads
-100% remote jobs
-Work from anywhere
-For digital working nomads
🔗 Link: https://lnkd.in/efQwAr7V
12. Simply Hired (simply hired.com)
13. Angel List (angel.co/Jobs)
14. Virtual Vocations (virtaalvocations.com)
15. Stack Overflow Jobs (Stack Overflow.com/Jobs)
16. Remote co (Remote.co)
17. Dice (dice.com)
18. Jobspresso (Jobspresso.co)
19. Upwork (upwork.com)
20. Outsourcely (Outsourcely.com)
21. Europe Remotely (europeremiely.com)
22. We work Remotely (weworkremotely.com)
23. Remote ok Europe (remoteok.io/Europe)
24. Flex Jobs (flexjobs.com)
25. Remole of Asia (remoteok.io/asia)
26. Outsourcely: Connect with remote job opportunities and freelance gigs.
🔗 Link (https://lnkd.in/gD32kSAV)
27.remote4me : Customize your remote job search based on location, salary, and more.
🔗 Link (https://remote4me.com/)
28. AutoApply.Jobs
With one click, auto-apply to jobs without any human effort.
29. FinalScout
Transform your LinkedIn connections into email lists with this ChatGPT-Powered Email Finding Extension.
30. Yoodli Al:
Enhance your online meeting job interviews with private, real-time speech coaching.
Coding
Links Úteis
Vagas
| HiringCafe |
Speech vs Text
| ElevenLabs |
Media
| Pexels |
Inteligência Artificial
| Hugging Face | Groq (API) | LM Studio |
| Consensus | AI-Pro | Replicate (API) |
Engenharia de Prompt
| Prompt Hero (imagem) | Github S1 S2 S3 S4 S5 S6 | Youtube S1 S2 |
Apostilas e Livros
| Scribd S2 |
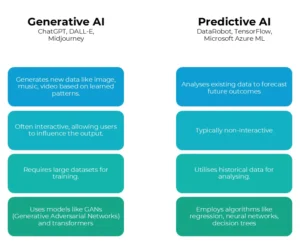
IA Generativa vs IA Preditiva
A contribuição da IA vem em duas formas principais: generativa e preditiva. No artigo a seguir, exploraremos as distinções entre IA generativa e preditiva, mostrando como cada tipo está moldando o futuro da resolução de problemas em vários campos.
IA generativa é um tipo de inteligência artificial que pode criar novas informações, como texto, imagens, música ou até mesmo vídeos, com base nos dados em que foi treinada. Em vez de apenas analisar ou processar informações existentes, ela gera novas ideias e resultados.
Imagine que você peça a um modelo de IA generativa como o ChatGPT para escrever uma história curta sobre um dragão e uma princesa. A IA usa o que sabe sobre narrativa, personagens e tramas para criar uma história completamente nova. Ela não apenas copia histórias existentes; ela combina ideias de maneiras criativas para gerar algo único.
Em uma aplicação prática, a IA generativa pode ser usada na arte. Por exemplo, um modelo de IA pode se inspirar em milhares de pinturas e criar uma obra de arte totalmente nova que nunca foi vista antes, misturando estilos e técnicas de maneiras inovadoras.
IA Preditiva
IA preditiva se refere à tecnologia que usa dados, algoritmos e aprendizado de máquina para prever resultados futuros com base em dados históricos. Ela analisa padrões e tendências para fazer suposições fundamentadas sobre o que pode acontecer a seguir.
Por exemplo, imagine uma loja que quer saber quantos sorvetes estocar para o verão. A loja analisa dados de vendas de verões anteriores, incluindo fatores como temperatura, eventos locais e promoções. Usando IA preditiva, a loja analisa esses dados para encontrar padrões, como como dias quentes levam a mais vendas de sorvete.
A IA prevê que em dias em que a temperatura estiver acima de 30°C, as vendas de sorvete aumentarão em 50%. Com base nessa previsão, a loja decide estocar mais sorvete em dias ensolarados, garantindo que eles tenham o suficiente para os clientes sem estocar demais.
Embora ambos os tipos de IA sejam poderosos, eles atendem a propósitos diferentes. Vamos entender as principais diferenças.
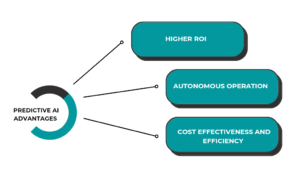
IA preditiva – vantagens
Enquanto a IA generativa atrai atenção por seus novos recursos na criação de conteúdo, a IA preditiva continua sendo uma ferramenta poderosa para melhorar a eficiência operacional e gerar economias substanciais de custos em processos de negócios estabelecidos.
Maiores retornos sobre o investimento
A IA preditiva aprimora as operações existentes, levando a melhorias significativas de eficiência. Por exemplo, a UPS, empresa de serviços globais de remessa e logística, economiza US$ 35 milhões anualmente ao otimizar rotas de entrega, enquanto os bancos podem economizar milhões ao prever com precisão transações fraudulentas. Essa tecnologia tem um histórico comprovado de entrega de altos retornos por meio de processos sistemáticos que as empresas já estabeleceram.
Operação Autônoma
A IA preditiva geralmente funciona sem intervenção humana, tomando decisões instantâneas com base na análise de dados. Por exemplo, ela pode aprovar automaticamente transações de cartão de crédito ou otimizar posicionamentos de anúncios em sites. Em contraste, a IA generativa geralmente requer supervisão humana, pois suas saídas precisam ser revisadas quanto à precisão e qualidade, tornando-a menos adequada para tarefas totalmente automatizadas.
Custo-efetividade e eficiência
Os modelos de IA preditiva são tipicamente muito mais leves e menos intensivos em recursos em comparação aos modelos complexos usados em IA generativa. Enquanto os modelos generativos podem consistir em centenas de bilhões de parâmetros e exigir dados extensos para treinamento, os modelos preditivos geralmente precisam de apenas alguns milhares de parâmetros, tornando-os mais fáceis e baratos de implantar.
A IA generativa substituirá a IA preditiva?
A IA generativa e a IA preditiva atendem a propósitos e funções diferentes, fazendo com que uma não seja uma substituição direta da outra. Embora a IA generativa possa aprimorar modelos preditivos (por exemplo, gerando cenários ou simulações com base em previsões), ela não pode substituir totalmente as capacidades analíticas da IA preditiva. Cada uma tem seus pontos fortes e aplicações, e elas podem se complementar em vários campos, mas não são intercambiáveis.
O que reserva o futuro?
O futuro está em investir corretamente para alavancar a parceria entre IA preditiva e generativa. A IA generativa se destaca na criação de conteúdo e soluções inovadoras, enquanto a IA preditiva se concentra na previsão de tendências e otimização de decisões. Juntas, elas aprimoram as operações comerciais, levando a valor mensurável e ROI aprimorado.
Por exemplo, na área da saúde, a IA preditiva prevê resultados de pacientes, permitindo intervenções oportunas, enquanto a IA generativa pode ajudar a criar planos de tratamento personalizados. Em finanças, a IA preditiva analisa dados de mercado para aprimorar estratégias de negociação, enquanto a IA generativa pode auxiliar na simulação de vários cenários de investimento.
Essa sinergia entre IA generativa e preditiva não apenas simplifica processos e aumenta a lucratividade, mas também promove o engajamento do cliente por meio de experiências personalizadas. As empresas que aproveitam os pontos fortes de ambas as tecnologias podem impulsionar eficiências operacionais, responder às necessidades do mercado rapidamente e manter uma vantagem competitiva.
No cenário em evolução da IA, a integração estratégica de capacidades generativas e preditivas é a chave para desbloquear todo o seu potencial, garantindo que as empresas obtenham retornos imediatos enquanto se preparam para um futuro definido pela inovação da IA.
Curso Python 3 – Udemy
Este post documenta comandos e fontes do curso da Udemy – Curso de Python 3 do básico ao avançado
Install Python
sudo apt update -y sudo apt upgrade -y sudo apt install git curl build-essential -y sudo apt install gcc make default-libmysqlclient-dev libssl-dev -y sudo apt install python3.10-full python3.10-dev -y
Ativar ambiente virtual
- Criar um diretório – ex: /opt/projetos-python/
- $ python3 -m venv .venv
- $ source .venv/bin/activate
- Para desativar $ deactivate
- $ wich python (demonstra qual ambiente está rodando)
- $ pip install pymysql (instala as libs do MySQL)
- $ pip install requests
- $ pip install –upgrade pip
- $ python -m pip install pip –upgrade (para atualizar o pip)
- Para remover o ambiente, basta apagar a pasta (neste caso .venv)
Fontes
https://gist.github.com/luizomf/8623264cbf69cd2619bcdee258628f41
https://gist.github.com/luizomf/688c8a48fe007829c120818138ac2317
Documentação do Python: Ex: https://docs.python.org/3.13/library/string.html
API Canônica
Uma API canônica é uma interface de programação de aplicação (API) projetada para ser a representação oficial, ou “fonte única da verdade”, de um sistema ou domínio. O conceito de canônica refere-se a algo que segue um padrão autorizado ou é a forma mais pura e completa de algo.
No contexto de APIs, isso significa que a API canônica é a interface principal, geralmente abstrata e agnóstica à tecnologia, que expõe o modelo de domínio de maneira consistente e clara para consumo por diferentes partes do sistema ou por sistemas externos.
Características principais de uma API canônica:
- Consistência:
Uma API canônica garante que diferentes consumidores (módulos internos, sistemas externos, etc.) acessem as mesmas regras e dados de forma consistente, sem variações ou duplicações em diferentes partes do sistema. - Independência de implementação:
Ela é projetada para ser neutra em relação a detalhes de implementação. Ou seja, ela descreve a interação com o sistema de maneira lógica e orientada ao domínio, sem expor detalhes técnicos ou internos, como infraestruturas ou frameworks específicos. - Modelagem orientada ao domínio (DDD):
APIs canônicas geralmente são construídas com base em modelos de domínio bem definidos, conforme os princípios de Domain-Driven Design. Cada endpoint ou operação exposta pela API reflete as operações de negócio reais, em vez de operações puramente técnicas. - Contrato Estável:
A API canônica geralmente apresenta um contrato estável e bem-definido, o que significa que ela pode evoluir sem quebrar a compatibilidade com os consumidores existentes. Isso permite atualizações e mudanças no sistema subjacente sem afetar diretamente os clientes que consomem essa API. - Facilidade de integração:
APIs canônicas padronizam a interface entre sistemas, facilitando a integração de novos componentes ou serviços. A interoperabilidade é simplificada, pois a API segue uma estrutura que pode ser consumida por diferentes tipos de clientes, como front-ends, back-ends ou terceiros. - Unificação dos dados e regras de negócio:
A API canônica centraliza e unifica o acesso aos dados e às regras de negócio, o que evita redundâncias e inconsistências. Isso garante que todos os consumidores obtenham a mesma visão e apliquem as mesmas regras de maneira padronizada.
Exemplo prático:
Em um sistema de e-commerce com um domínio que inclui clientes, pedidos e produtos, uma API canônica exporia operações que permitem a criação de pedidos, consulta de produtos, gerenciamento de clientes, etc., de forma que todos os serviços relacionados interajam com esses dados e regras de uma maneira consistente.
- Operações do domínio:
- Criar um pedido (
/orders/create) - Consultar um produto (
/products/{id}) - Gerenciar clientes (
/customers/{id}/update)
- Criar um pedido (
Benefícios de usar uma API canônica:
- Reduz complexidade e duplicidade: Uma API canônica elimina a necessidade de várias APIs especializadas ou duplicadas para diferentes sistemas, centralizando as operações.
- Facilita manutenção e evolução: Com um contrato estável e bem definido, a API pode ser evoluída sem grandes impactos para os consumidores.
- Melhor modelagem de negócio: Reflete com precisão os processos de negócio e o modelo de domínio, melhorando a clareza e a robustez do sistema.
Essencialmente, a API canônica é um ponto de acesso estruturado e padronizado para todo o domínio de um sistema, garantindo consistência e governança.
Placa de som Ubuntu 24.04
Este procedimento resolve o problema de placa de som não ser reconhecida, típico problema “Saída Fictícia”.
Você precisa adicionar essas duas linhas no final de /etc/modprobe.d/alsa-base.conf
opções snd-hda-intel model=auto
blacklist snd_soc_avs
É exatamente isso que ele está fazendo:
opções snd-hda-intel model=auto:
Esta linha configura o comportamento do driver snd-hda-intel, responsável por manipular áudio de alta definição (geralmente associado a placas de som Intel) no Linux.
A opção model=auto permite que o driver detecte automaticamente o codec de áudio usado pelo seu hardware e selecione as configurações de modelo apropriadas para ele. Isso é útil quando a configuração padrão não se alinha perfeitamente com os recursos do hardware, potencialmente resolvendo problemas em que certas funcionalidades de alto-falante ou microfone não são reconhecidas corretamente.
lista negra snd_soc_avs:
Esta linha impede que o módulo snd_soc_avs seja carregado pelo kernel Linux. snd_soc_avs significa Sound Open Firmware Audio DSP para plataformas Intel com sincronização de áudio e vídeo, que pode fazer parte do tratamento de som em sistemas Intel modernos.
Ao colocar este módulo na lista negra, você evita que ele interfira com o driver principal snd-hda-intel. Parece que, no seu caso, snd_soc_avs estava causando conflitos ou não era totalmente compatível com sua configuração de áudio específica, levando aos problemas que você estava enfrentando. Ao impedi-lo de carregar, você permite que o sistema dependa de outros módulos, talvez mais compatíveis, para lidar com o processamento de áudio.
Fonte: https://askubuntu.com/questions/1511648/audio-not-working-ubuntu-24-04
ChatGPT – Dicas
Usando campos semânticos e variáveis
Me escreva um artigo sobre primeiros passos no Docker, em tom de conversa com uma criança de 10 anos. Agora, use os itens em {RESUMO) para o
{ROTEIRO} seguindo as {REGRAS}
{RESUMO}
[Autoridade]: Felipe, um desenvolvedor Fullstack
[Avatar]: Desenvolvedores Júniors
[Problema]: Como instalar o Docker
{ROTEIRO}
Olá eu sou [Autoridade] e vou ajudar o [Avatar]
Hoje vamos resolver o [Problema]
{REGRAS}
> Siga o {ROTEIRO) acima e substitua os elementos entre [ ]
por aqueles listados em {RESUMO} acima.
> Mantenha o tom e ritmo, mas reescreva as palavras em {ROTEIRO} para que seja diferente do original, expandindo ou mudando conforme necessário.
> Use analogias simples e hipérboles
Prompts assertivos
Prompts ricos – modelo de perguntas
Me [FUNÇÃO] um [TIPO DE TEXTO] sobre [assunto] nesse [estilo]
FTAE
Função: (escreva/resuma/traduza/crie tópicos)
Tipo de texto: (roteiro/post para blog/artigo/poema/postagem para instagram)
assunto: (I.A, futebol, música, filme... etc)
estilo: (personalidade, escritor, filósofo)
Me [crie tópicos] um [um artigo] sobre [macarrão]
Me [escreva] um [TEXTO] sobre [INTELIGÊNCIA ARTIFICIAL]
Tom de voz
Escreva para quem aquela comunicação deve ser direcionada para calibrar o entendimento e naturalidade da resposta
Tom de voz: me explique como se fosse (para uma criança de 10 anos, de um jeito mais sênior
Exemplos:
Me escreva em formato de carrossel do instagram uma postagem sobre programação com os princpais me explicando o que é DOCKER em um estilo informal e descontraído como se tivesse sido postado por um influencer de tecnologia, explique como se fosse para uma criança de 10 anos
Me escreva em formato de carrossel do instagram uma postagem sobre programação com os princpais me explicando o que é DOCKER em um estilo informal e descontraído como se tivesse sido postado por um influencer de tecnologia, explique com um tom de voz mais sênior
ChatGPT – Prompts
Best side hustles
Act as financial advisor. Provide a list of the most priftable side hustles to start in 2024. Include detailson potential earnings, required skills, and initial investment needed.
Hig-paying side jobs
Act as a career consultant. Suggest a list of high-paying side jobs to apply for in 2024. Include information on the average pay, necessary qualifications and how to get started.
Business ideas
Act as an entrepreneur coach. Provide a list of profitable business ideas I can start with an initial investment of [AMOUNT]. Include steps to get started, potential profit margins and tips for success.
SWOT analysis
Act as a personal development coatch. help me coduct a SWOT analysis of myself. Guide me through iidentifying my strengths, weaknesses, opportunities and threats, and suggest strategies to leverage this analysis for financial success.
Passive income
Act as a financial strategist. Suggest ways to Create a passive income stream. Provide a list of potential passive income sources, Such as rental properties, dividend stocks, or online businesses, an explain how to start with each.
Best skills to learn
Act as a career coach, Recommend skills to learn in 2024 that can significantly increase my earning potential, Include Informatlon on how to acquire these skills, potentlal job and business opportunities, and expected salary increases.